榜单更新,大模型密集发布周,究竟孰强孰弱?|xbench月报
进入四月,多家公司连续发布了新的模型,包括GPT-5.5、Claude Opus4.7、Deepseek-v4、Kimi2.6、hy3、Qwen3.6。xbench对最新的模型从科学推理、多模态、真实行业任务等维度进行了评测,并更新了leaderboard。
结合本期重点模型与产品的公开发布信息来看,本轮迭代呈现出3个非常清晰的方向:
- 原生多模态能力成为模型训练的主流叙事,视觉能力正在从基础的“看图回答”进入复杂任务执行链条。
- 长链路、Agentic Coding继续成为头部模型发布的主线。Opus4.7、Kimi K2.6、Qwen3.6、Hy3都把复杂代码库理解、多步调试、工具调用、前端生成、长程执行作为核心能力升级方向。
- 开源模型继续追赶顶尖闭源模型,超长上下文正在从高端能力变成基础设施能力。
结合本期重点模型与产品的公开发布信息来看,提升模型的原生多模态能力已经是大厂的主流叙事。视觉理解正在被接入复杂任务的执行链条。
但一个反复出现的现象是,在现有模型的基础上提升多模态能力时,长文本和推理能力在跑分和用户体验上会出现明显下降。这里的原因在于如果视觉能力是在文本预训练完成后才通过微调加入,模型已经在大量参数token的纯文本训练中高度特化,此时注入视觉信息,模型必须在一个已经定型的表示空间中为新模态腾出位置,新的多模态对齐过程就会覆盖旧的语言能力,尤其是长文本理解和多步推理这类对内部表示一致性要求最高的能力。
模型在做的事情不是往成熟的文本模型上加视觉,而是从预训练阶段就让文本和视觉共同演化,让两种模态在统一的表示空间中一起长出来。这条路线的价值在于让视觉成为模型推理链条的原生组成部分,使得agent在执行coding、design、数据分析等多步任务时可以无缝调用视觉上下文,而不需要在模态之间做脆弱的桥接。
xbench采用长青评估机制,持续汇报最新模型的能力表现,更多榜单未来将陆续更新,期待你的关注。你可以在xbench.org上追踪我们的工作和查看实时更新的Leaderboard榜单排名;欢迎通过team@xbench.org与我们取得联系,反馈意见。
xbench-ScienceQA Leaderboard更新
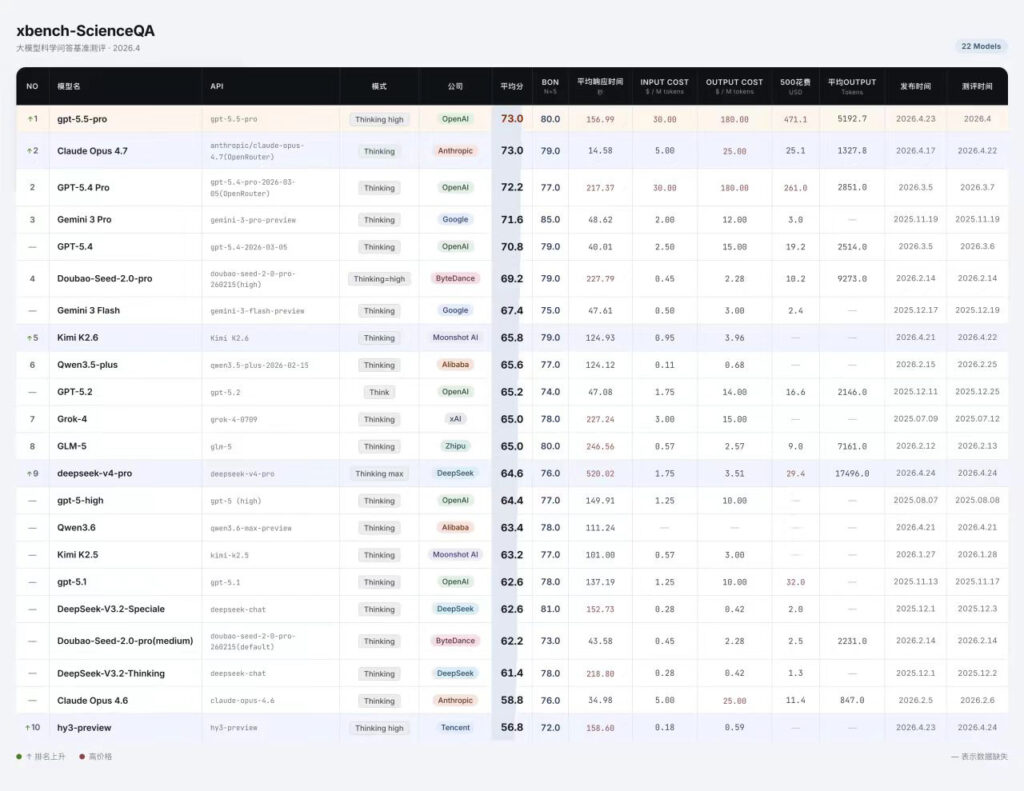
备注:一家公司有多个模型或多个版本时,排名中保留得分最高的版本。
ScienceQA榜单分析
GPT-5.5:
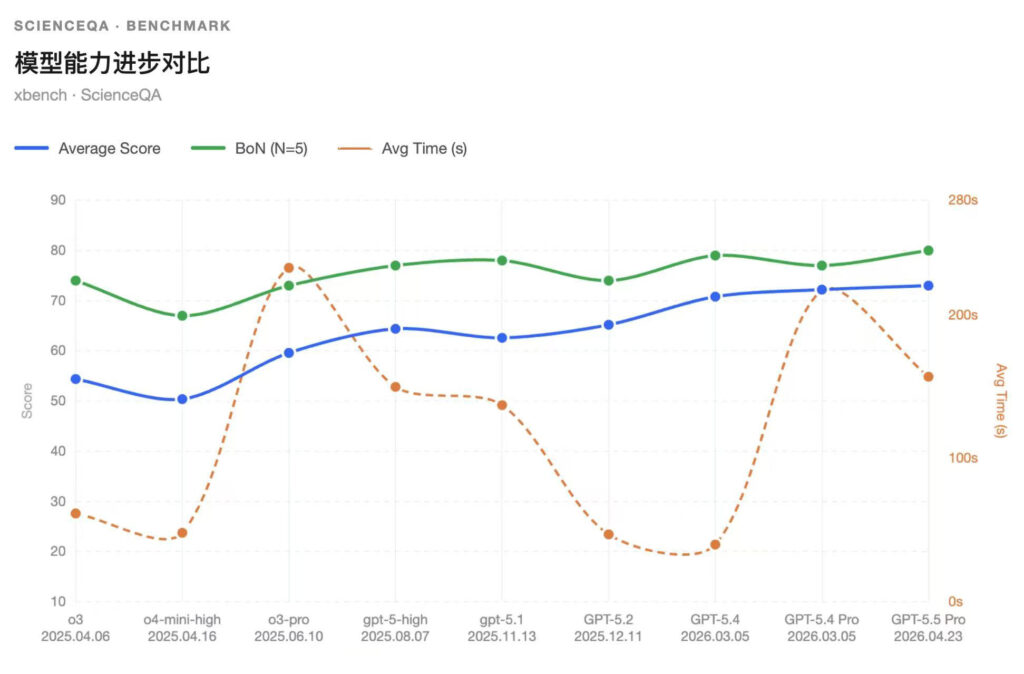
GPT5.5以73.0的平均分位并列第1,较上一代GPT-5.4 Pro的72.2分小幅提升0.8分,同时BoN(N=5)从77.0提升至80.0,说明GPT-5.5在头部能力已经接近饱和的情况下,仍进一步抬高了多次采样下的上限表现。相比GPT-5.2的65.2分,GPT-5.5提升7.8分,体现出OpenAI在复杂科学问答、长链路推理和稳定解题能力上的持续迭代。不过其平均响应时间仍处于较高水平,说明GPT-5.5的优势更多来自更强的推理预算。
Claude Opus4.7:
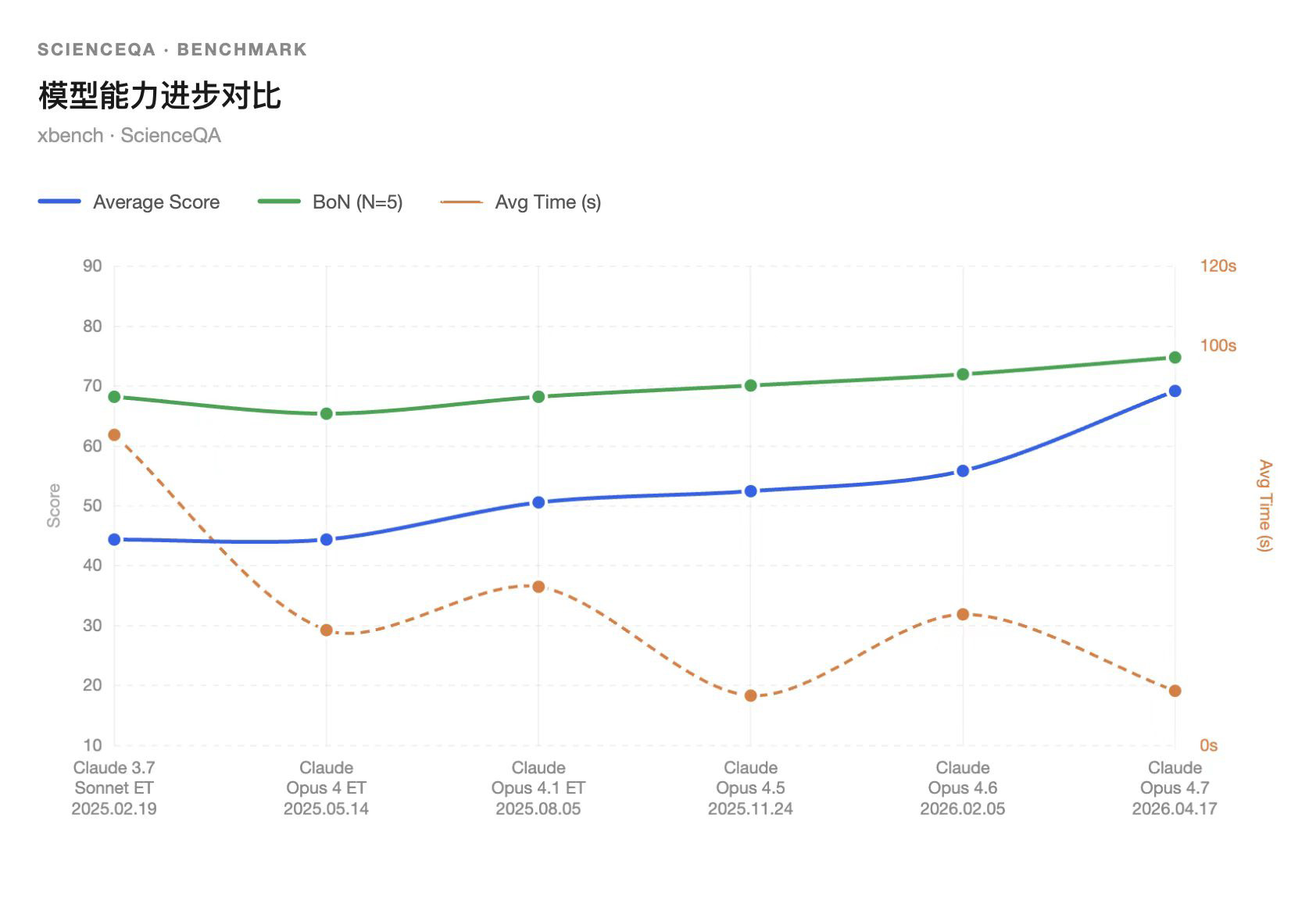
以73.0的平均分并列位列第1,较上一代Claude Opus4.6的58.8分大幅提升14.2 分,是Anthropic近期模型线中最明显的一次能力跃迁;同时BoN(N=5)从76.0提升至79.0,平均响应时间从34.98秒下降至14.58秒,说明Opus4.7不只是单点分数提升,而是在平均能力、采样上限和推理效率上同时改善。相比Claude Opus4.5的55.2分,Opus4.7已经把Claude系列重新推回ScienceQA头部梯队。
Kimi K2.6:
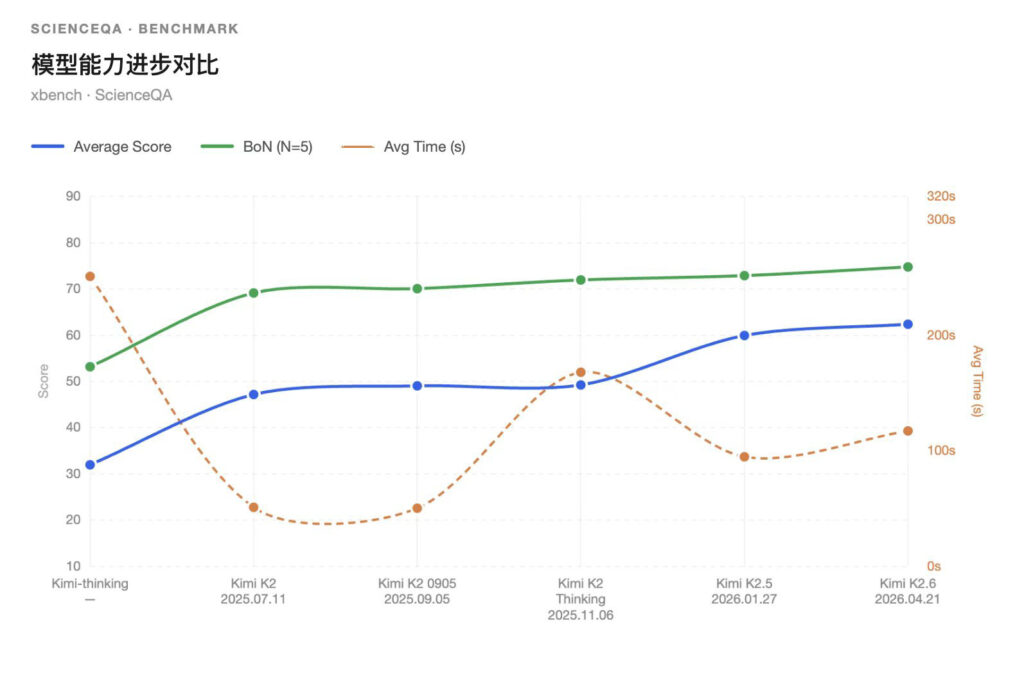
Kimi K2.6的平均分从Kimi K2.5的63.2提升到65.8,BoN从77.0提升到79.0,已经接近GPT-5.2、Qwen3.5-plus等中高位模型区间。放在Kimi横向对比,K2.6 相比Kimi K2 Thinking的51.8分已经提升14.0分,说明月之暗面过去几轮在 thinking、长上下文和工具调用上的训练积累,正在逐步反映到通用科学问答能力上。不过K2.6的平均响应时间达到124.93秒,较K2.5进一步上升。
DeepSeek-V4:
DeepSeek-V4-Pro以64.6的平均分高于DeepSeek-V3.2-Speciale和V3.2-Thinking,但76.0的BoN低于V3.2-Speciale的81.0。这说明新版本并不是在所有维度上刷新最高点,而是把能力重心转向了更宽的任务覆盖,尤其是1M长上下文、agentic coding和复杂代码库处理。
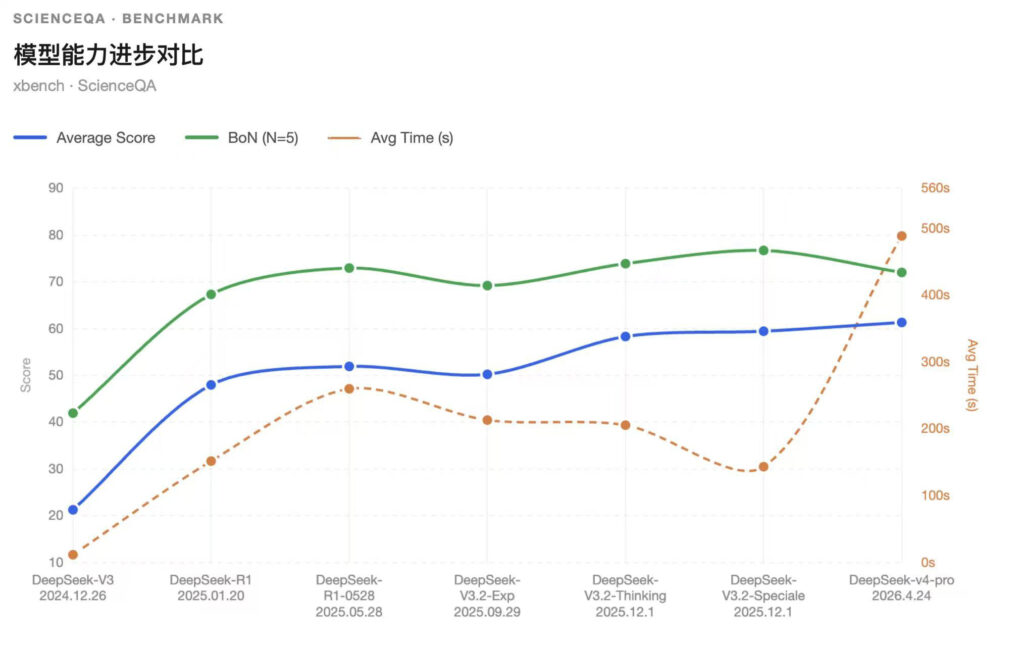
Qwen3.6:
Qwen3.6的平均分63.4低于Qwen3.5-plus的65.6,但BoN达到78.0,高于Qwen3.5-plus的77.0。Qwen3.6本身更强调长上下文、agentic coding和原生多模态能力,对比Qwen3.5-plus,平均响应时间更快,更具性价比。
Hy3 Preview:
Hy3 Preview以56.8的平均分进入榜单,更适合作为腾讯新一代基础模型路线的起点观察。它的BoN为72.0,说明模型在多次采样下能触及更高表现。
BabyVision Leaderboard更新
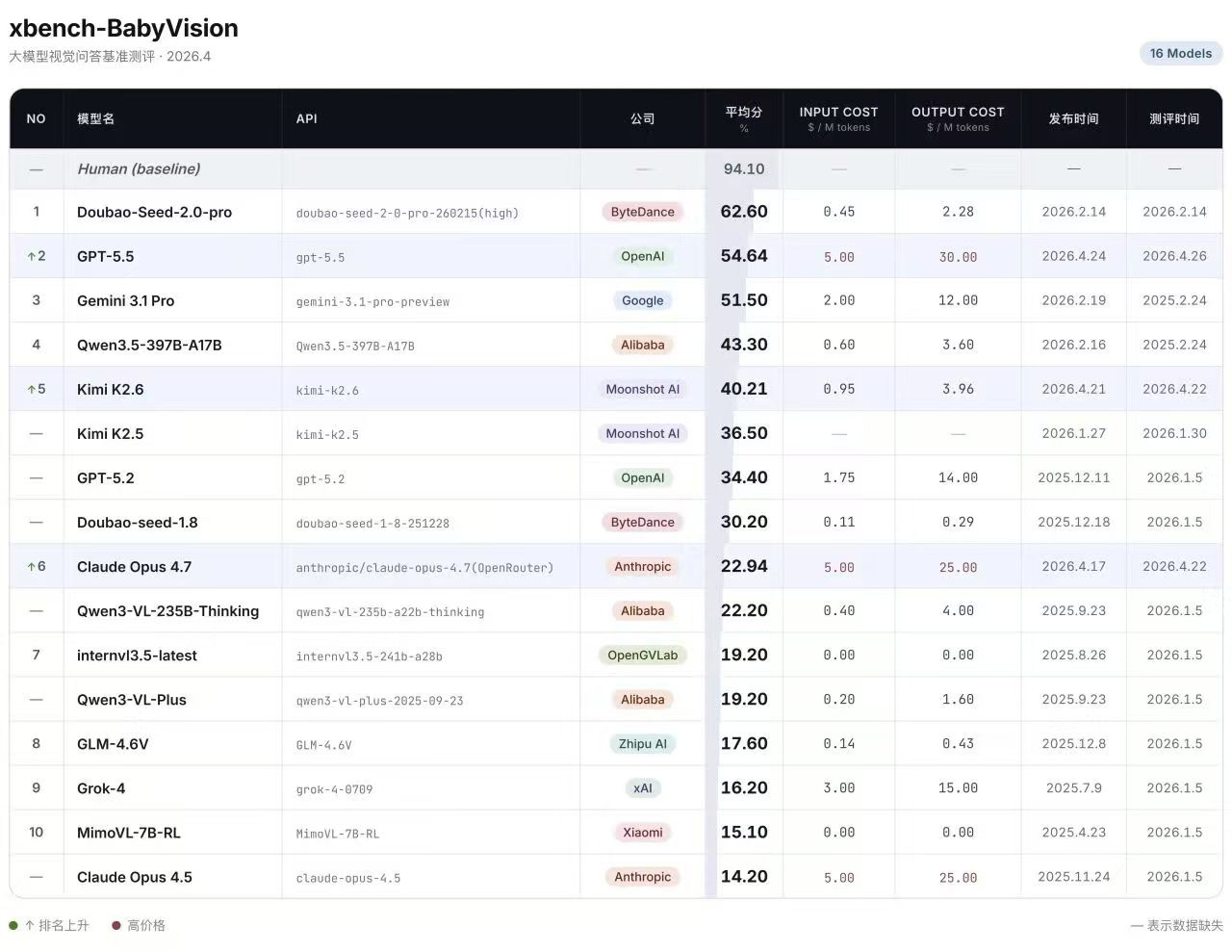
新发布的模型中,对GPT-5.5、Claude Opus4.6、Kimi K2.6的多模态能力进行了评测:
GPT-5.5在BabyVision上升至第2,54.64%的成绩已经超过Gemini 3.1 Pro的51.50%,GPT-5.5的多模态能力不再只是补齐短板,而是进入了头部竞争区间。相比GPT-5.2的34.40%,本次提升超过20个百分点,说明OpenAI在视觉理解上的迭代速度明显加快。不过它距离Doubao-Seed-2.0-pro的62.60%仍有接近8个百分点差距,头部视觉理解榜单里,字节Seed2.0仍是更强的SOTA。
Kimi K2.6在BabyVision上拿到40.21%,相比Kimi K2.5的36.50%有进步。这个结果说明K2.6在主要提升长程任务、代码执行和多Agent协作的同时,多模态视觉能力也得到了同步补强。纵向对比,它超过GPT-5.2和Doubao-seed-1.8,也说明月之暗面已经进入主流多模态模型区间。
Claude Opus 4.7在BabyVision上的提升明确:22.94%较Claude Opus 4.5的 14.20%有明显提升,证明新版本的多模态能力确实被加强。
$OneMillion-Bench Leaderboard更新
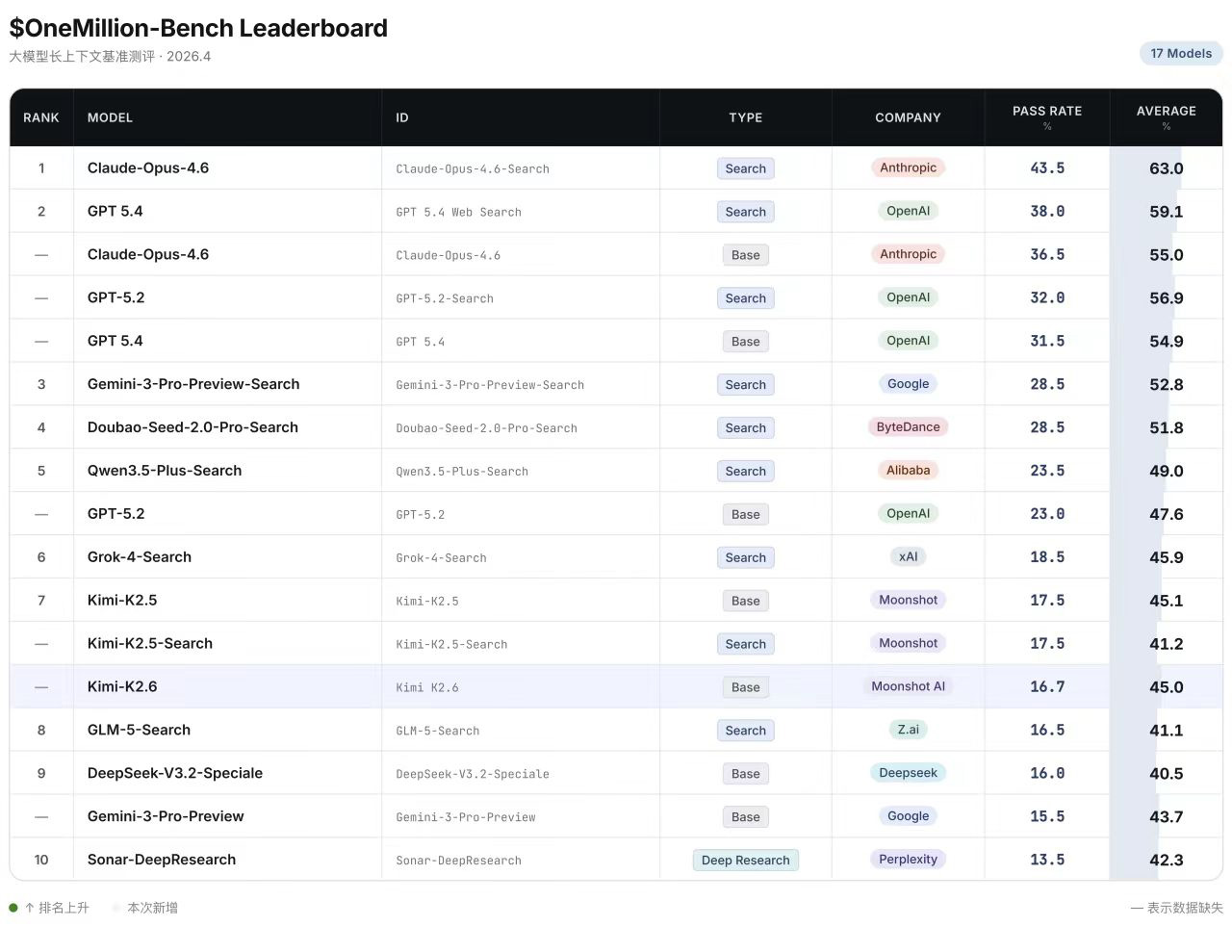
Kimi K2.6在这个基准测试集上表现和K2.5无明显差距,不具有统计学意义。
近期新发布模型总结
GPT-5.5
GPT-5.5是本轮所有新模型的frontier,尤其在coding能力上达到了当前SOTA水平。它的核心提升不只是代码生成,而是把长上下文推理、工具调用和自我纠错整合到同一个工程执行栈里;在Codex中,GPT-5.5更像一个能持续工作的工程agent,可以围绕复杂repo完成问题定位、调试、测试和多轮迭代。与此同时,GPT-5.5也把这套agentic execution能力扩展到research、data analysis、document-heavy tasks和跨工具操作。代价是成本明显上升:标准GPT-5.5的API单价约为GPT-5.4的2倍,但其在Codex场景中完成相同任务所需token更少,部分抵消了单价上涨带来的实际成本压力。
Claude Opus4.7
Claude Opus4.7的核心升级是多模态理解和长链路工作流稳定性。相比前代,Opus4.7支持更高分辨率图像输入,能够处理密集截图、复杂图表、专业软件界面和需要像素级参考的任务。对agent场景来说,这相当于补强Claude的视觉输入层,让模型在computer use和前端任务中更准确地理解屏幕状态。同时,Opus4.7在指令遵循和长程任务预算上继续增强。新增的task budget让模型在完整agent loop中感知token预算,并在任务推进过程中更好地分配思考、工具调用和最终输出。实际体验上,Opus4.7更适合需要多轮修改、跨文件记忆和最终交付质量的工作流。
Kimi K2.6
Kimi K2.6是月之暗面新发布的开源MoE模型,采用1T总参数、每个token激活32B参数的稀疏架构。相比K2.5,K2.6在无需人工干预的长时间自主运行场景中提升尤为明显:Agent集群规模从100个子Agent扩展到300个子Agent,可以一次性交付代码、文档、网页、PPT和表格等复杂工作流。它的核心价值在于把长程coding、多Agent协作和持续工具调用整合进完整的agent产品场景,使开源模型开始具备更接近团队式交付的任务执行能力。
DeepSeek-V4
DeepSeek-V4作为开源模型继续逼近主流闭源模型表现,并把1M超长上下文推向开源场景。DeepSeek-V4-Pro在agentic coding、世界知识和推理能力上和上一代相比显著提升,使用体验已经接近主流闭源模型;DeepSeek-V4采用MoE与DSA稀疏注意力机制,重点解决1M长上下文下的计算与显存压力。DeepSeek-V4对长上下文效率的处理让长代码库、长文档、企业知识库和持续运行的agent更可用,降低了成本。
腾讯Hhy3
Hy3 Preview是腾讯混元基础模型的一次重要重启。官方模型卡显示,Hy3是295B总参数、21B激活参数的MoE模型,支持256K上下文,重点提升复杂推理、指令遵循、上下文学习、coding和agent tasks。
阿里Qwen3.6
Qwen3.6这一轮同步更新开源和云端闭源模型:开源模型服务开发者生态,云端 Max-Preview承接更高能力上限。Qwen3.6相比上一版本在世界知识、指令遵循和agentic coding上有明显提升,这轮Qwen不再只强调参数规模或通用能力,而是更聚焦真实开发任务:理解代码库、调用工具、生成前端、处理复杂指令。对于企业和开发者来说,这类能力更接近实际生产力。