xbench榜单更新!DeepSeek V3.2追平GPT-5.1|xbench月报
xbench最新一期Leaderboard出炉啦!
本期AGI Tracking中的xbench-ScienceQA榜单,有6家公司发布了新模型。xbench对所有新模型第一时间进行了评测,Gemini 3 Pro刷新SOTA,DeepSeek V3.2分数追平GPT-5.1,且性价比极高。
xbench近期将会发布2个新的benchmark,分别用来评估Agent指令遵循能力和模型多模态理解能力。
xbench采用长青评估机制,持续汇报最新模型的能力表现,更多榜单未来将陆续更新,期待你的关注。你可以在xbench.org上追踪我们的工作和查看实时更新的Leaderboard榜单排名;欢迎通过team@xbench.org与我们取得联系,反馈意见。
Science-QA Leaderboard更新
备注:
- 汇率取1USD=7.1491CNY
- 本次评估基本涵盖了截至排行榜发布之日主流大语言模型(LLMs)的公开可用应用程序编程接口(APIs),未公开发布的内测模型未列入榜单。
- 如果一家公司有多个模型,优先测试最新版本和官方网站推荐的模型。所有模型均关闭搜索功能。
- 一家公司有多个模型时,排名中保留每家公司的最新模型版本。当同一推理模型存在不同的推理成本时,仅保留得分最高的版本。
01 ScienceQA榜单分析
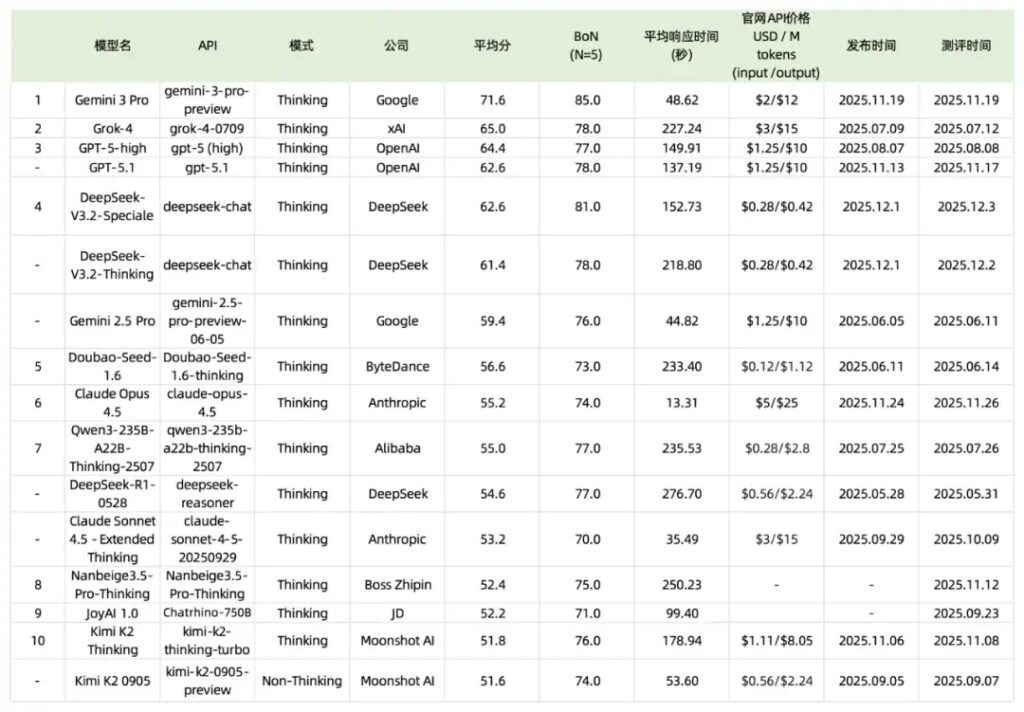
截至于2025年12月初,模型分数更新如下:
Gemini 3 Pro:Gemini 3 Pro与此前Gemini 2.5 Pro相比,平均分从59.4提升到71.6,BoN(N=5)达到85分。Gemini 3 Pro平均处理每到题目的时间仅49s。根据消耗token数和API费用,粗略统计模型跑完ScienceQA的500道题的成本,GPT-5.1花费是$32,Gemini 3 Pro的花费仅是$3。
DeepSeek V3.2:DeepSeek-V3.2-Speciale较DeepSeek-R1-0528有较大提升,达到62.6分,和GPT-5.1持平。BoN(N=5)达到81分,成为Gemini 3外,第二家突破80分的公司。与此同时,DeepSeek V3.2的价格远低于GPT-5.1。评测ScienceQA的500道题的总花费,GPT-5.1需要$32,DeepSeek-V3.2-Speciale仅需$2,DeepSeek-V3.2-Thinking为$1.3。
Claude Opus 4.5:Claude Opus 4.5较Claude Sonnet 4.5-Extended Thinking有小幅提升,达到55.2分。但推理速度非常亮眼,每道题的平均耗时只有13s,远快于其他模型。
Kimi K2 Thinking:Kimi K2 Thinking平均分为51.8分,BoN(N=5)为76分,均有小幅提升。
02 开源模型测试
针对市场上不断涌现的开源模型和API,xbench团队也自己搭建了环境,并部署进行了评测。由于不同环境对模型评测结果会有一定影响,因此未直接纳入Leaderboard榜单进行对比。评测时部署的环境和配置如下:
Tongyi DeepResearch
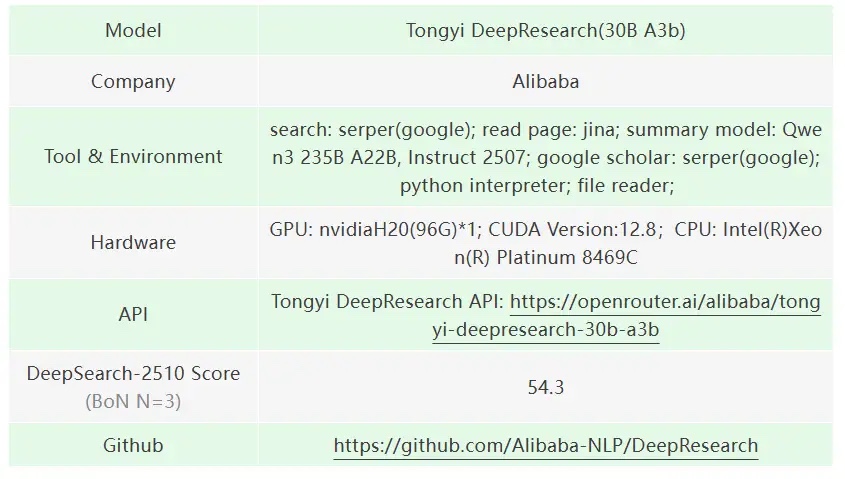
Tongyi DeepResearch面向深度信息检索及推理任务的能力,在一个总参数30B激活参数3B的模型下,达到了一个非常有竞争力的水平,在xbench-DeepSearch评测集中达到54.3分。对论文作者主张的“在Agent领域,经过良好训练的小模型可以比肩大模型的效果” ,是一个很好的实测案例。
MiniMax-M2

近期新发布模型和产品总结
DeepSeek V3.2
DeepSeek V3.2是深度求索(DeepSeek-AI)推出的新一代开源大语言模型,旨在平衡卓越的推理能力与高效的 Agent 表现。在架构层面,该模型创新引入了 DeepSeek Sparse Attention(DSA)机制,在保持长上下文(Long-Context)性能的同时显著降低了计算复杂度,解决了传统注意力机制在长序列下的效率瓶颈。
在后训练阶段,DeepSeek V3.2 采用了可扩展的强化学习框架(Scalable RL Framework)。该框架将后训练阶段的算力投入提升至预训练成本的10%以上,通过改进GRPO算法实现了大规模强化学习的稳定训练,从而显著增强了模型的推理和指令遵循能力。
此外,针对Agent场景,DeepSeek V3.2构建了大规模Agent任务合成流水线(Large-Scale Agentic Task Synthesis Pipeline)。该流水线能够自动生成数千个虚拟环境和数万条复杂指令,不仅解决了开源社区在复杂交互数据上的短板,还首创了“思考融入工具使用”(Thinking in Tool-Use)的能力,打破了以往模型在思考模式下无法调用工具的局限,实现了推理与行动的深度融合。
最终,DeepSeek V3.2在通用场景下大幅降低了计算开销与用户等待时间;其高算力版本DeepSeek-V3.2-Speciale更是在IMO 2025和IOI 2025中斩获金牌级表现,展现了媲美甚至超越闭源前沿模型(如 Gemini-3.0-Pro)的极致推理能力。
Gemini 3
Gemini 3是Google DeepMind于2025年推出的全新一代多模态大模型,代表了当前人工智能在推理深度、多模态理解与智能体协作方面的较高水平。作为Gemini系列的最新演进,Gemini 3不仅在HLE、GPQA Diamond、MathArena Apex等权威基准上刷新成绩,更以1501 Elo的成绩登顶LMArena排行榜,展现出接近博士级的综合推理能力。其核心突破在于深度融合文本、图像、视频、音频与代码的跨模态理解,并凭借百万级上下文窗口和增强的Vibe Coding能力,可零样本生成高度交互的网页、3D游戏乃至科学可视化内容。
Gemini 3还引入“Deep Think”深度推理模式,在解决新颖复杂问题(如 ARC-AGI-2)时表现尤为突出。在应用层面,它不仅赋能普通用户学习家常食谱、分析运动视频、理解科研论文,还通过全新智能体开发平台Google Antigravity实现端到端自主编程与任务执行,支持从邮箱整理到商业模拟等长周期规划。Gemini 3并已全面集成至Search、Gemini应用、Vertex AI及第三方开发环境,开启“智能体优先”的新范式,让AI真正成为用户的学习伙伴、创造引擎与行动助手。
Nano Banana Pro
Nano Banana Pro(基于Gemini 3 Pro图像模型)是Google DeepMind推出的全新图像生成与编辑模型,代表了当前AI视觉创作的前沿水平。它深度融合Gemini 3 Pro的先进推理能力与实时世界知识,不仅能生成高度逼真、上下文丰富的图像,还能在画面中精准渲染多语言文本,实现从手绘草图到高保真视觉作品的一站式转化。其创新之处在于将语义理解、实时信息检索(如天气、菜谱)与视觉生成无缝结合,支持多达14个输入元素的复杂合成,并能保持最多5个人物的身份一致性。
此外,Nano Banana Pro提供专业级创意控制,包括局部编辑、光影调整、景深切换及多分辨率输出,适用于广告、影视、教育和设计等多个领域。为增强AI透明度,所有生成图像均嵌入SynthID数字水印,用户可通过Gemini应用验证内容来源,兼顾创造力与责任伦理。
Claude Opus 4.5
Claude Opus 4.5是Anthropic于2025年11月推出的旗舰大模型,标志着AI在代码生成、智能体协作和人机交互领域的重大跃进。该模型在真实世界软件工程任务(如 SWE-bench Verified)中创下行业新高,不仅能高效编写多种语言的高质量代码,还能在复杂系统中自主推理、权衡取舍,甚至以创造性方式解决超出基准预期的问题,展现出类人的灵活性与策略思维。
Opus 4.5在数学、多语言理解、视觉推理等通用能力上也全面领先,并显著优化了推理效率:凭借新的“努力程度”参数和上下文压缩技术,它在使用更少token的同时实现更强性能,特别适合构建长时间运行、多智能体协同的自动化工作流。该模型已全面集成至Claude应用、Claude Code、Excel插件及桌面端,支持从日常办公到专业开发的广泛场景,同时通过SynthID类水印机制增强内容可追溯性,推动AI能力与责任并重的演进。
GPT-5.1
GPT-5.1是OpenAI对GPT-5系列的一次重要迭代,包含GPT-5.1 Instant和GPT-5.1 Thinking两个版本,兼顾日常对话的流畅性与复杂任务的深度推理能力。该模型不仅在数学、编程等硬技能上显著提升,更在“人性化”交互上实现突破——语言更温暖、共情更自然,能根据上下文动态调整思考深度,在简单问题上快速响应,在复杂任务中则展现出更强的坚持性与条理性。
GPT-5.1引入自适应推理机制,能自主判断是否需要深入“思考”再作答,从而在准确性和效率之间取得更优平衡。与此同时,OpenAI大幅优化了用户对ChatGPT个性的控制能力,新增“专业”“直率”“俏皮”等预设语气,并支持对简洁度、温度、表情符号使用等维度进行细粒度调节,甚至可在对话中主动建议调整风格。这些改进让GPT-5.1不仅更聪明,也更“懂你”,适用于从情绪支持、旅行规划到技术解释、职场协作等广泛场景,标志着大模型正从工具向真正个性化的智能伙伴演进。
Kimi K2 Thinking
Kimi K2 Thinking是Moonshot AI推出的开源推理大模型,以“思考型智能体”为核心理念,突破了传统大模型在多步复杂任务中的局限。其关键技术特点包括:支持200–300步连续工具调用的长程推理能力、基于测试时扩展(test-time scaling)的动态思考机制、高效稀疏MoE架构(1 万亿参数仅激活 32 亿)、以及原生INT4量化带来的2倍推理加速。
K2 Thinking 在Humanity’s Last Exam、BrowseComp、SWE-Bench等权威基准上超越GPT-5与Claude,展现出顶尖的工具协同、编码与网络搜索能力。更难得的是,它以仅460万美元的训练成本、宽松的开源许可(修改版 MIT 协议)和低硬件门槛(如两台 M3 Ultra 即可部署),打破了“大模型必须重资本”的行业定式,为开发者提供了高性能、低成本、可商用的推理模型新选择。
Tongyi Deepresearch
Tongyi DeepResearch是阿里巴巴通义实验室专为深度研究任务设计,具备自主规划、搜索、推理和知识综合能力的智能体模型。该模型采用了结合了中期训练(mid-training)和后训练(post-training)的端到端训练框架,这一框架将强化学习和监督微调相结合,逐步提升模型能力。在中期训练阶段,模型通过大规模、高质量的合成数据集建立起强大的Agent先验知识,后训练则通过强化学习进一步提高模型的Agent能力。
此外,Tongyi DeepResearch在数据合成方面采用了完全自动化的合成数据生成管线,避免了人工标注的高成本,并确保每个训练阶段都有针对性的高质量数据支持。这些合成数据不仅具有高扩展性和快速验证的特点,还能够生成超越人类能力(super-human-level)的任务数据,极大提升了模型在复杂任务中的表现。
Tongyi DeepResearch最终在总参数30B激活参数3B的小模型上,实现了比肩闭源大模型的深度推理和信息检索能力,突破了开源模型的局限,为社区开发者和研究人员提供了新的选择。
如公司已上线发布的产品想参与评测和Leaderboard榜单,可以联系xbench团队。