Kimi K2:全球首个完全开源的Agentic模型
7月11日,Moonshot AI正式发布了Kimi K2模型,并同步开源。它具备更强代码能力、更擅长通用Agent任务的MoE(Mixture-of-Experts,混合专家)架构基础模型,总参数1T(1万亿),激活参数32B。
“大”参数在AI界其实已经算不上什么新闻了,Kimi K2真正引起广泛惊叹的,是它作为“Agentic AI”的定位——它专为Agent工作流而设计,能够更准确地理解你的复杂意图,拆解任务,并自主调用工具去完成它,甚至完成复杂的多步骤流程。
也就是说,它不只是一个聊天机器人,更是一个能理解复杂指令、自主调用工具来解决问题的“数字员工”。
我们认为,Moonshot AI的Kimi K2是一个为Agentic任务设计的MoE大模型, 具有很强的自主执行多步任务与工具调用的能力,同时编程任务中也表现出非常卓越的性能,具备和Claude Sonet 4、Gemini 2.5和GPT 4.1同等水准的能力。作为Agentic model里面唯一一个完全开源的模型,推动了全球开源社区的进步。从它的身上,我们看到了中国的新一代优秀的创业者在曲折中保持着一路向上的力量。
“行动派”AI,不止于“大”
首先,它采用了典型的稀疏MoE架构。这种架构将不同专家网络分配给不同输入,使得模型能够根据任务需求动态激活相应的专家模块,从而实现更高效的参数利用率。具体而言,Kimi K2拥有1万亿总参数量,激活参数为320亿,模型包含384个专家,每个token会选择8个专家进行计算,同时设置1个共享专家以提高模型的通用性。
你可以把它想象成一个拥有1万亿个“专家”的智囊团。当你提出一个问题时,系统会激活其中最相关的320亿参数来为你服务。这样做的好处是,既能拥有巨大模型的知识和能力,又能保持很高的运行效率。
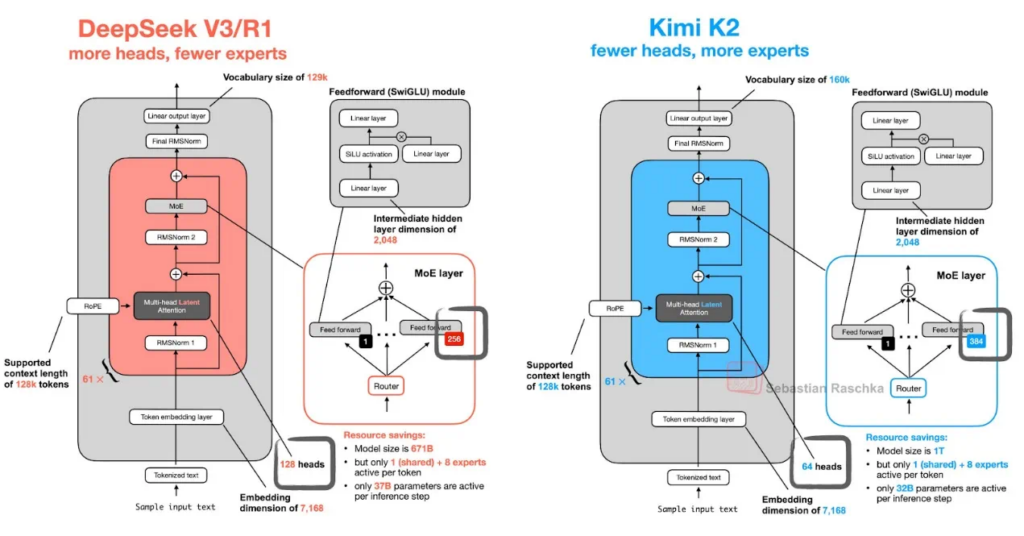
来源: Sebastian Raschka
同时,Kimi K2还进行了大规模Agentic Tool Use数据合成,构建了可大规模生成多轮工具使用场景的合成pipeline,覆盖数百领域、数千工具。高质量样本由LLM评估筛选后用于训练。
Kimi K2不仅在可验证任务上(代码、数学)强化学习,还通过引入自我评价机制(self-judging),解决了不可验证任务的奖励稀缺问题。通过可验证任务持续优化critic,提升泛化任务表现。
其次,在训练过程中,Kimi K2使用了改进的MuonClip优化器,有效解决了大规模优化过程中梯度不稳定与收敛困难的问题,使得模型能够在15.5万亿tokens的预训练规模下保持稳定。该算法通过定期调整注意力机制中的关键参数,成功避免了大模型常见的“训练崩溃”问题。
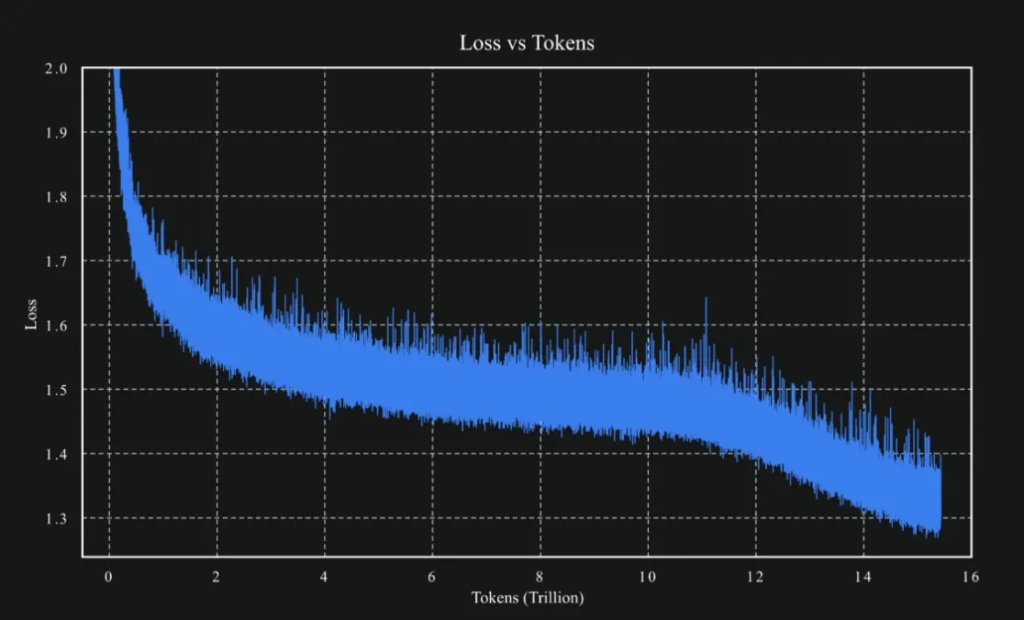
Kimi K2在使用MuonClip优化器预训练15.5万亿个token期间的损失曲线。这条平滑下降的轨迹——没有不稳定的峰值或平台期——表明MuonClip能够在数万亿个token的训练过程中,维持大规模大语言模型训练的稳定性。
当然,超长上下文能力也很重要。Kimi K2的最大上下文长度达到128K,这使其能够更好地处理长文档理解、长对话以及大规模检索任务。
性能表现方面,在SWE Bench Verified、Tau2、AceBench等基准性能测试中,Kimi K2均取得开源模型中的SOTA成绩,展现出在代码、Agent、数学推理任务上的领先能力。
AI圈掀讨论热潮
Kimi K2的横空出世,已在全球AI圈掀起讨论热潮。这种热度的背后,是业界对其技术突破的认可,更是对其开源价值的期待。
英伟达创始人黄仁勋在在北京参加链博会期间多次高度评价Kimi。他表示,开源具有全球性的影响。开源模型不仅助力中国的生态系统,也在为全球各地的生态系统提供支持。Moonshot AI的Kimi非常出色,是当今世界上最优秀的推理模型之一。。

这种认可正在转化为实际的合作动能。随着Kimi K2的发布,其海外影响力快速渗透至产业端:OpenRouter、Cline、微软旗下Visual Studio Code等全球知名编程平台纷纷宣布接入Kimi K2。
在开发者与研究者圈层,Kimi K2的口碑同样突出。AI从业者纷纷表达对这一新型开源模型的赞美。独角兽公司Perplexity CEO Aravind Srinivas表示,基于Kimi K2模型的出色表现,公司将会利用K2进行后训练。
全球最大开源AI社区Hugging Face联合创始人Thomas Wolf表示,不断突破极限挑战闭源的K2模型令人难以置信,Kimi团队在过去几个月里推出的系列模型让人印象深刻。
国际顶尖学术期刊《自然》在网站上刊登文章称“Kimi K2引起轰动,是‘又一个DeepSeek时刻’”。文章还引用了美国知名AI研究员Nathan Lambert的点评称,Kimi K2是“全球最新最好的开源模型”。
科技媒体人Azeem Azhar在文章中表示,Moonshot AI的Kimi K2模型成本低廉、性能卓越且开源。尤其是K2在使用MuonClip优化器预训练15.5万亿个token期间的损失曲线,被AI研究员Cedric Chee称为“机器学习史上最优美的损失曲线之一”。
下面,就让我们一起看看Kimi K2在其他不同能力测试中的表现:
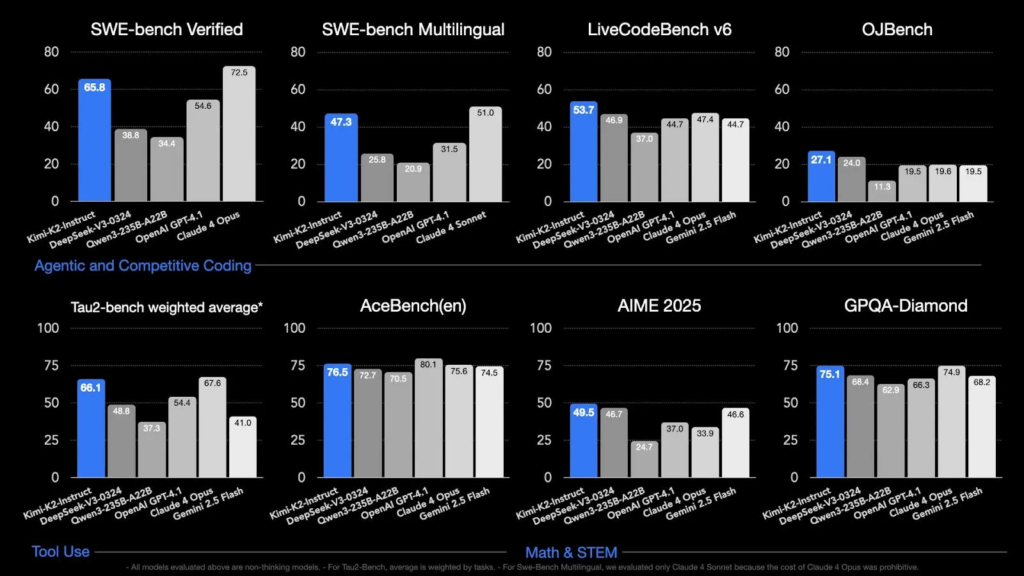
Kimi K2 在一系列基准测试中的表现。
编程能力
Kimi K2在编程领域的表现尤为出色。在LiveCodeBench编程基准测试中,Kimi K2的准确率达到了53.7%,超越了GPT-4.1(44.7%)。Kimi K2在OJBench的得分也达到了27.1%。
这两个评测分别模拟互动式编程任务与传统竞赛题,进一步证明了Kimi K2在软件工程场景中的适配能力。
在前端开发任务中,Kimi K2擅长生成兼具设计感与视觉表现力的代码,支持粒子系统、可视化和3D场景等表现形式,具备较强的图形能力与交互性。以下是用Kimi K2生成的山川峡谷3D景观,支持昼夜循环。
Agent工具调用能力
Kimi K2现已具备稳定的复杂指令解析能力,可将需求自动拆解为一系列格式规范、可直接执行的ToolCall结构。在SWE-bench Verified测试中Kimi K2的单次尝试准确率达到了65.8%,不仅超越了大多数开源模型,还与某些专有模型表现相当。
这个测试评估的是模型在真实开源项目中识别与修复代码错误的能力,难度极高。
比如,将13万行的原始数据丢给Kimi K2,它可以帮你分析远程办公比例对薪资的影响,分析显著差异,自动生成统计图表与回归模型解读,并用统一色调做出小提琴图(violin plot) 、箱线图(box plot)、散点图(scatter plot)等专业图表,整理成报告。
多任务综合表现
- 在Tau2-bench的加权平均值测试中,Kimi K2的表现达到了66.1%,显示出其在复杂STEM任务上的强大能力;
- 在AceBench(英文)测试中,Kimi K2的准确率达到了80.1%,进一步证明了其在语言理解和生成方面的优势;
- 在多语言测试如MMLU-Pro中,它同样进入领先梯队,兼具多语言与跨学科能力,同时也印证了Kimi K2的空间理解与复杂结构表达能力;
- 在数学和科学领域,Kimi K2在AIME、GPQA-Diamond和MATH-500等测评中稳定优于主要对手,展示出深度数学建模的潜力;
- Kimi K2还登顶了EQ-Bench3和Creative Writing v3这两个评测集。EQ-Bench3是用来测试LLM情商的基准测试,Creative Writing v3是用来测试LLM创意性写作能力的基准测试。
如今,Moonshot AI已经将Kimi K2的模型权重和代码都放在了Hugging Face和Github上,采用非常宽松的MIT许可证。这意味着任何开发者都可以免费使用、修改和分发这个模型,用它来打造自己的AI应用。而其API及定价也是以4元/百万输入tokens和16元/百万输出tokens“惊艳”了海内外。
从国内开发者基于其搭建个性化应用,到海外平台争相接入,再到学术界与产业界的一致认可,Kimi K2的影响正沿着开源的脉络向全球扩散。
未来,随着开发者生态的持续壮大,以及模型在思维链推理等方向的进一步优化,Kimi K2或许会带来更多惊喜。而它所开启的“行动派 AI”时代,也将让AI从“对话工具”走向“生产力引擎”,在代码开发、数据分析、复杂任务处理等场景中,为全球用户创造更具体的价值——这,正是Kimi K2留给行业的最大启示:AI的终极竞争力,从来不止于“大”,更在于“能做事、做成事”。