Grok-4登顶,Kimi K2非思考模型SOTA,豆包、DeepSeek新模型性能提升|xbench月报
自一个月前xbench公布第一期Leaderboard以来,AI大模型界又迎来了新一轮的“你追我赶”。
上周,xAI发布了“全球最强大的”Grok-4,两天后,Kimi推出并开源了“一万亿参数”的K2模型。xbench对这两个“新玩家”火速进行了测评,并发布新一期双轨评估体系(Dual Track)AGI进程(AGI Tracking)系列的科学问题解答测评集(xbench-ScienceQA)榜单。
xbench采用长青评估机制,每月持续汇报最新模型的能力表现,更多榜单未来将陆续更新,期待你的关注。你可以在xbench.org上追踪我们的工作和查看实时更新的Leaderboard榜单排名;欢迎通过team@xbench.org与我们取得联系,反馈意见。
Science-QA Leaderboard更新
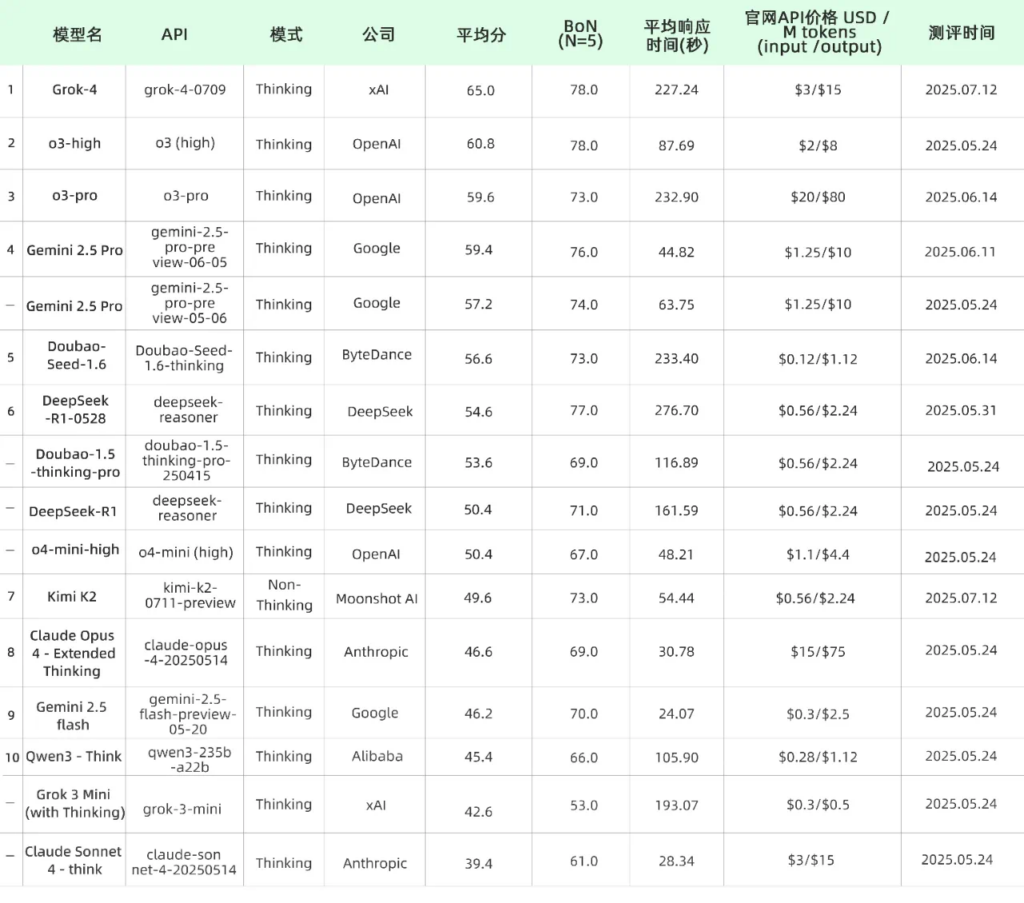
备注:
- 汇率取1USD=7.1491CNY
- 本次评估基本涵盖了截至排行榜发布之日主流大语言模型(LLMs)的公开可用应用程序编程接口(APIs),未公开发布的内测模型未列入榜单。
- 如果一家公司有多个模型,优先测试最新版本和官方网站推荐的模型。所有模型均关闭搜索功能。
- 一家公司有多个模型时,排名中保留每家公司的最新模型版本。当同一推理模型存在不同的推理成本时,仅保留得分最高的版本。
- 榜单含Thinking和Non-Thinking模式,未区分成两个榜单,榜单前10中Kimi K2为Non-Thinking模型,其余均为Thinking模型。
随着推理模型的飞速发展,经典学科评测集如MMLU、MATH等已接近满分,无法继续度量模型能力的进展。博士研究生水平的学科知识和推理能力评测集如GPQA、SuperGPQA、HLE等成为新的评测标准,获得了业界的认可与关注。考虑到研究生水平的题目数截止于2025年7月14日,与5月26日发布的Leaderboard相比,有6家模型发布的版本更新进入前10:
- Grok-4:Grok-4相比同为推理模型的前作Grok-3-mini,在ScienceQA评测集上实现了42.6分至65.0分的巨大提升,提升了约50%。Grok-4超越了OpenAI的o3模型,成为ScienceQA评测集上的SOTA模型。
- o3-pro:OpenAI o3-pro(medium)版本在ScienceQA评测集上达到59.6分,比o3(medium)的54.4分有一定提升,与o3(high)的60.8分相近。但模型的响应时间变长、API价格增加。
- Gemini 2.5 Pro 0605:相比于同一模型的前序0506版本,价格不变,性能小幅提升到59.4分。
- Doubao Seed 1.6:相比于Seed的前一版本Seed-1.5-pro,分数从53.6提升至56.6,同时相比1.5版本API价格下降约50%。
- DeepSeek R1-0528:相比R1的前一版本,ScienceQA分数由50.4提升至54.6。
- Kimi K2:最新的Kimi K2模型在ScienceQA中得分49.6,在榜单中位于Non-Thinking模型第一,BoN(N=5)分数为73.0,位居头部梯队。
在此测评集中,对来自16家公司的43个不同版本的模型进行了测试。模型得分的分布情况如下:
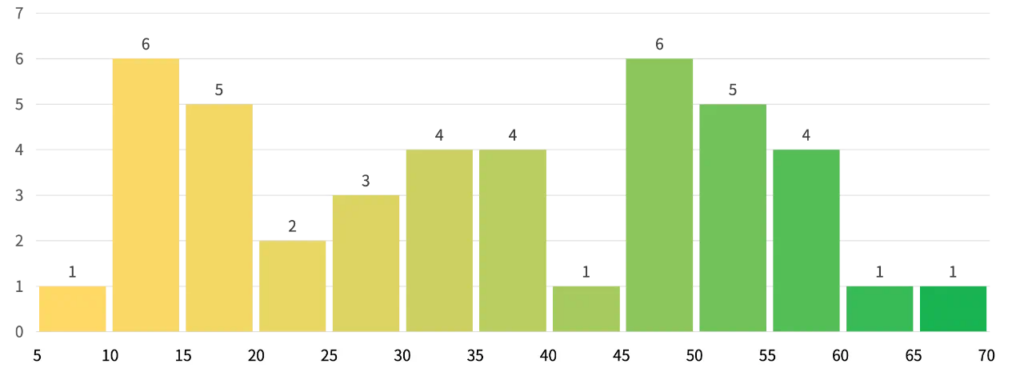
整体变化:xAI的Grok-4登顶SOTA、Moonshot AI的Kimi K2进入前10,OpenAI、Google、ByteDance 、DeepSeek、Anthropic等厂商的主流模型在xbench-ScienceQA榜单上的偏序和此前保持一致。
模型性能对比
下图的横轴为API输出价格(USD/百万tokens),纵轴为xbench-ScienceQA平均分。
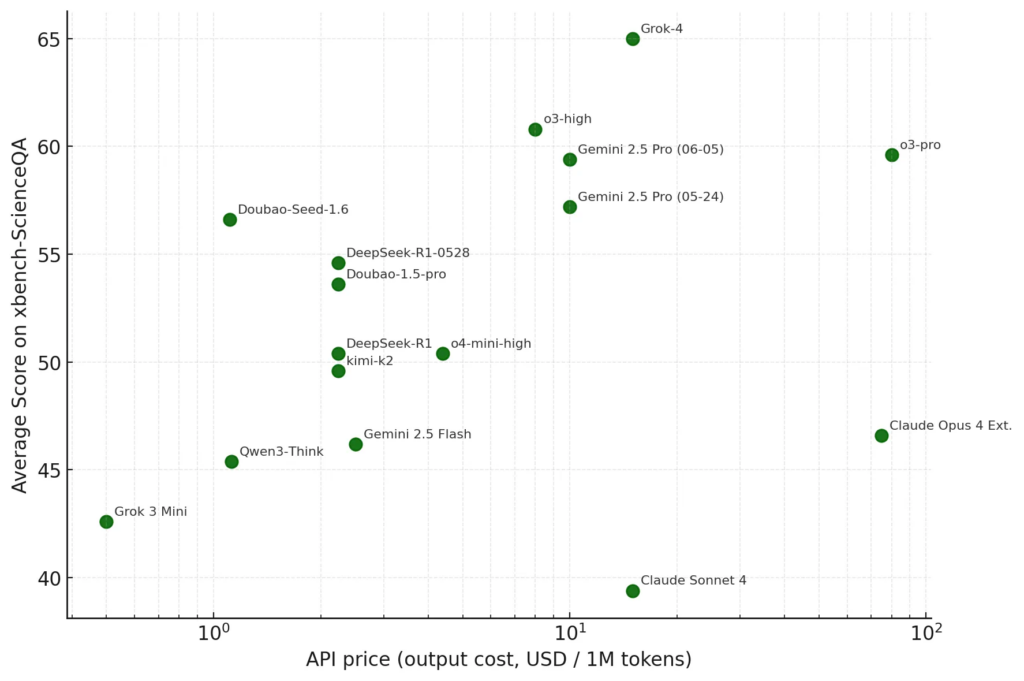
- 高质高价区:Grok-4、o3-pro、Gemini 2.5 Pro处于右上方,分数领先但成本也显著较高。Grok-4有更好的表现,且输出价格$15只有o3-pro($80)的1/4不到,在同档模型中最具竞争力。
- 性价比区:Doubao-Seed-1.6在保持56.6分高分的同时,输出价格只需$1.1。与DeepSeek-R1同属于最具性价比的模型。
响应速度对比
图的横轴为平均响应时间,纵轴为xbench-ScienceQA平均分。
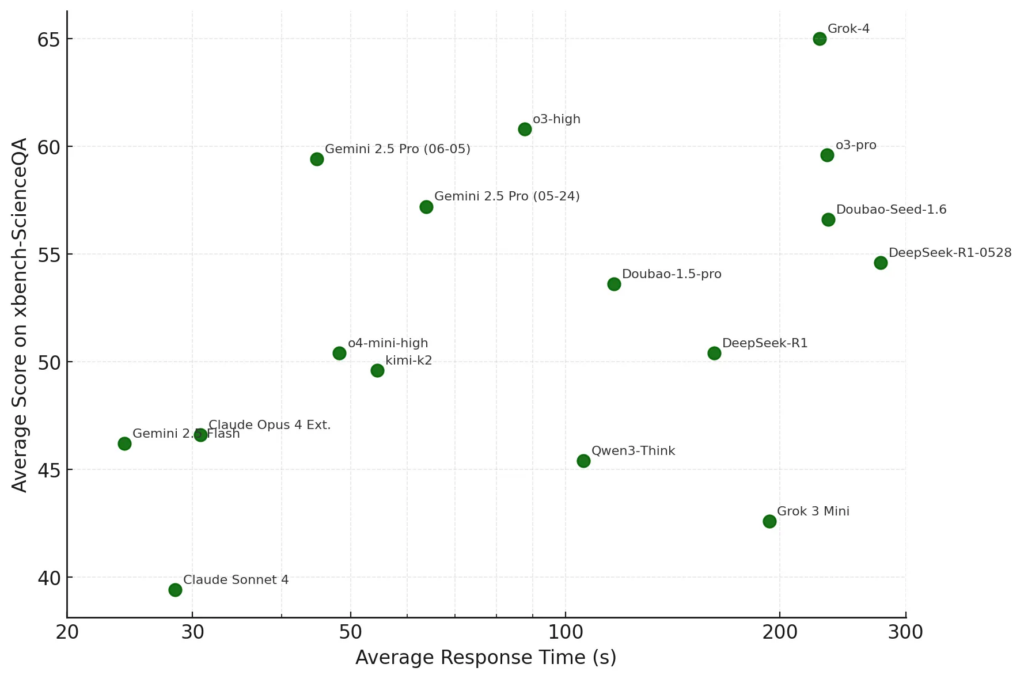
- 深度推理模型:推理模型整体表现出推理时间越长,分数越高的趋势。Grok-4分数最高,平均回复时间(227s)也是最长的一档。Gemini 2.5 Pro在保持高分(59.4)的同时,平均回复时间不到50s,接近非推理模型,在性能和延时上做到了最佳的平衡。
模型成本对比
下图的横轴为API价格(output是主要成本),纵轴为xbench-ScienceQA的BoN得分(N=5)。
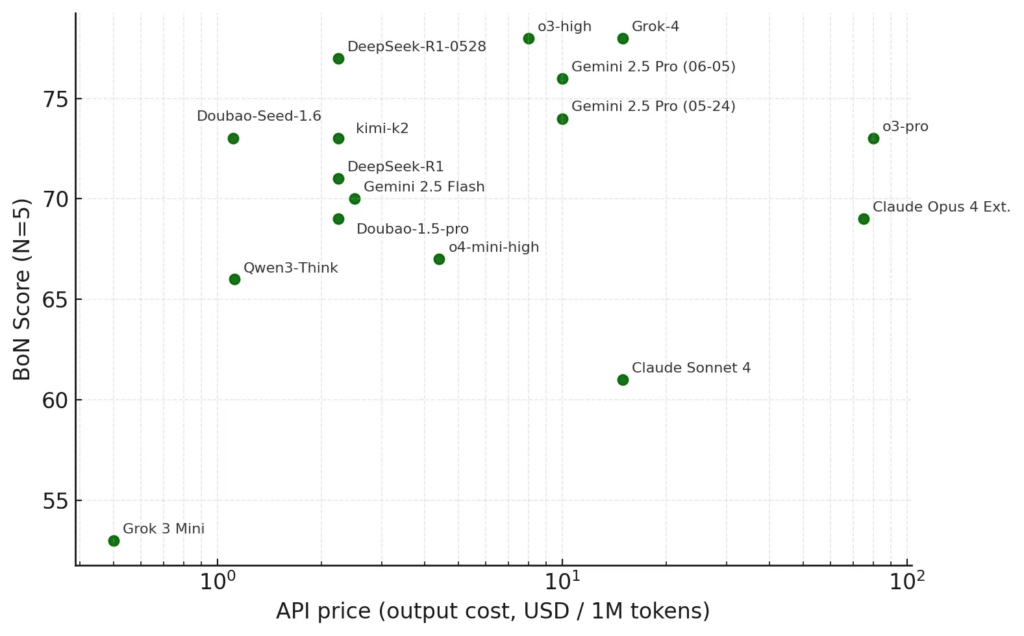
- BoN (N=5) 作为多步推理正确率指标,比平均分更直接反映模型在长链条任务中的潜在上限,可用来评估其作为Agent底座时能够达到的上限。
- Grok-4与o3-high以BoN=78并列总体第一,其次是DeepSeek-R1-0528(77)与Gemini 2.5 Pro 0605(76),但是DeepSeek的成本要显著更低。
- 在国产模型阵营里,在DeepSeek(77)居首,Doubao-Seed-1.6与Kimi K2(均73)并列第二,成本在同一区间,为开发者选择国产模型搭建复杂Agent时提供了更多的参考。
月度新模型和产品总结
Grok-4
Grok-4与Grok-4 Heavy是xAI于7月10日发布的全新推理模型,RL阶段使用了其前代Grok-3十倍的算力投入,获得了显著的智能飞跃。从基础版Grok-4,到支持原生工具调用的版本(Grok-4 w/Python+Internet),再到思考阶段引入了多智能体协作模块的Grok-4 Heavy,均横扫了人类前沿科学领域的各个榜单(AIME/GPQA/LiveCodeBench/…),并在象征着人类专家级别最困难的智能基准测试Humanity’s Last Exam中取得了前所未有的突破。
Grok-4在预训练过程中即融入了原生tool use能力,并在RL阶段注入了与预训练相当的算力,追求从“第一性原理”出发推导因果。在思考阶段,Grok-4引入了网页实时检索帮助事实判断,并设计了由多个不同智能体平行思考协作的分布式推理模块,并验证了这种test-time scaling在模型智能提取上的有效性。
Kimi K2
Kimi K2是Moonshot AI于7月11日发布的开源权重MoE模型,高达1T的总参数量,32B的激活参数量,384个专家的超稀疏结构,是迄今为止最大的开源模型。发布的版本中包含纯基座模型Kimi K2-Base与基于指令微调的Kimi K2-Instruct,两者均为未经过RL强化学习训练的非思考模型。但均已展现出出色的推理和agentic tool use能力。
Kimi K2万亿规模参数量的训练主要得益于其在预训练阶段的几大技术创新:首先,自创的MuonClip优化器实现15T token训练过程全程的高效稳定;自研的智能体模拟pipeline涵盖了数百场景数千工具,为模型在预训练阶段注入agentic tool use能力打下数据基础。
o3-pro
o3-pro是openAI于6月10日发布的推理模型,针对科学、编程、写作等领域做了专门优化,在可靠性上也有明显的提升。相比前代具有更强大的推理能力,更容易生成符合人类偏好的回答。
o3-pro引入了更长(数倍于o3)的思考时间,适应于超长上下文(200k token的窗口)任务,展现出了出色的上下文理解和推理能力,与之而来的是简单问题的过度思考现象。
评测集更新总结
xbench的两个评测集xbench-ScienceQA和xbench-DeepSearch已于6月18日正式开源。
开源地址: