Gemini 3.5 Flash性价比惊艳|xbench 快报
北京时间2026年5月19日,Google I/O 2026开发者大会正式开幕。Google一次性放出了两款新模型,面向agent与coding的Gemini3.5 Flash,以及”any-to-any”原生多模态生成模型Gemini Omni(首发版本Omni Flash)。
在Gemini3.5 Flash的官方公开评测中,其在Terminal-Bench2.1、MCP Atlas、Finance Agent v2等agentic与coding基准上的得分全面超越上一代Gemini3.1 Pro,同时官方API价格仅为3.1Pro的约60%,输出速度被官方描述为”4x faster than other frontier models”。在xbench的榜单中,在Gemini 3.5 Flash的性能没有明显下降的情况,性价比、推理token消耗、响应速度方面,显著好于GPT5.5 pro和Opus4.7,同样任务的API花费只有GPT-5.5 Pro的1/100。
ScienceQA Leaderboard更新
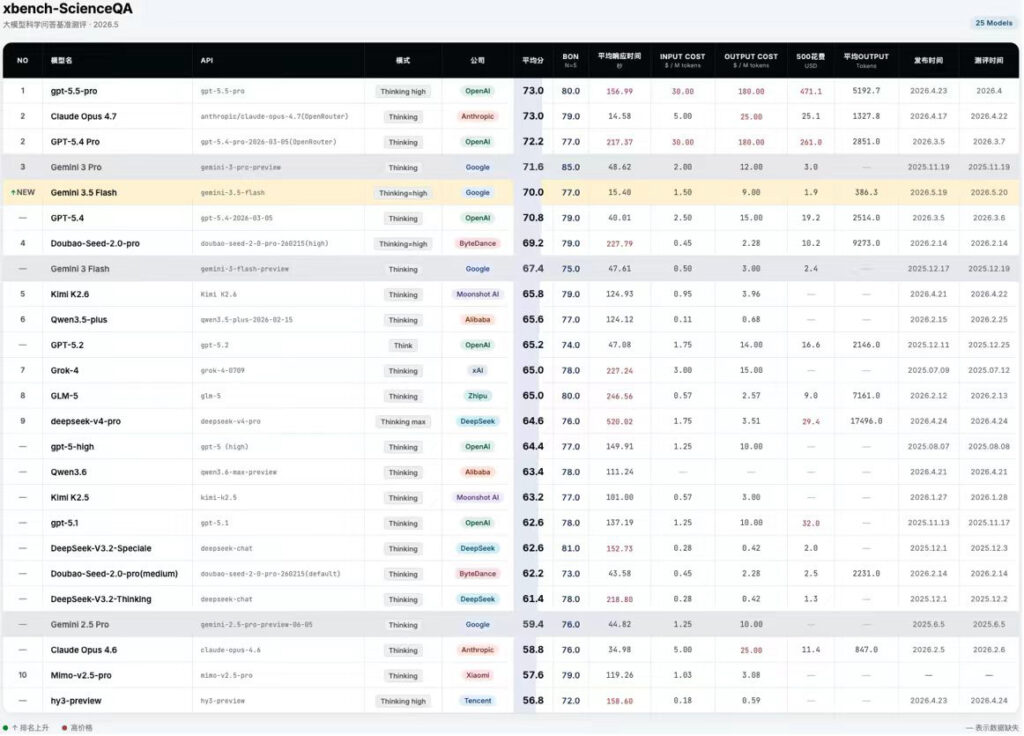
Gemini3.5 Flash在xbench-ScienceQA榜单上的位置:
- Gemini3.5 Flash在ScienceQA上为70分,位列第四,仅次于GPT5.5 pro、Opus4.7和Gemini3 pro;较上代Gemini3 pro分数略有降低,但是速度提升3倍,花费下降近40%。
- 同样500道题目,SOTA的GPT-5.5 Pro花费$471,Gemini3.5 Flash分数相近的情况下,仅仅花费$1.9,不足GPT的1/100,甚至比大部分国内模型还便宜。Token消耗数量,也只有其他模型的10-20%。体现了极致的性价比。
Gemini3.5 Flash:用Flash的价格做Pro级别的Agent
Gemini3.5 Flash在平均分上接近Gemini3 Pro,但响应时间缩短至1/3、500 题花费降至$1.9,把Pro级别的科学问答能力下放到Flash价位。
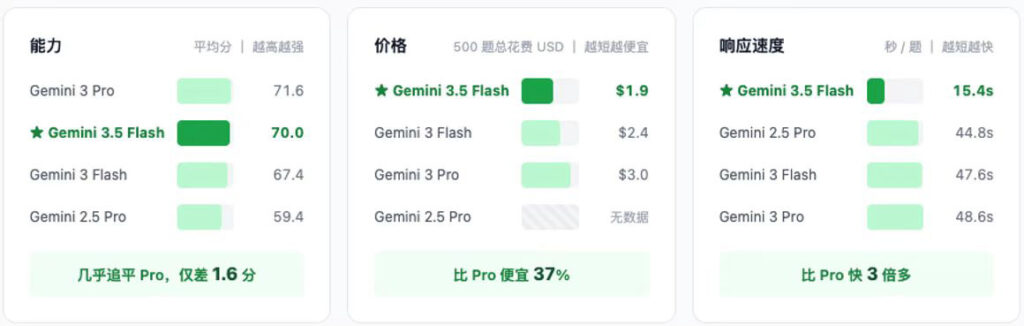
从上图可以看出,新发布的3.5 Flash模型在能力上紧贴着Gemini3 Pro,但同时在价格和延迟上显著优于Pro模型。
- 平均分70.0 vs Gemini 3 Pro的71.6,差距只有1.6分。但往前看一代Pro(Gemini 2.5 Pro 59.4),差距是10.6分。也就是说,今天的Flash模型从能力上看,基本已经能盖过去年同期的旗舰Pro,且优势接近一个完整代际。
- 价格和延迟才是这次的杀手锏。Gemini3.5 Flash把单题响应时间从Gemini3 Pro的48.62秒压到15.4秒,快3倍;跑完500题的总账单从$3.0降到$1.9,便宜37%。
BabyVision Leaderboard更新
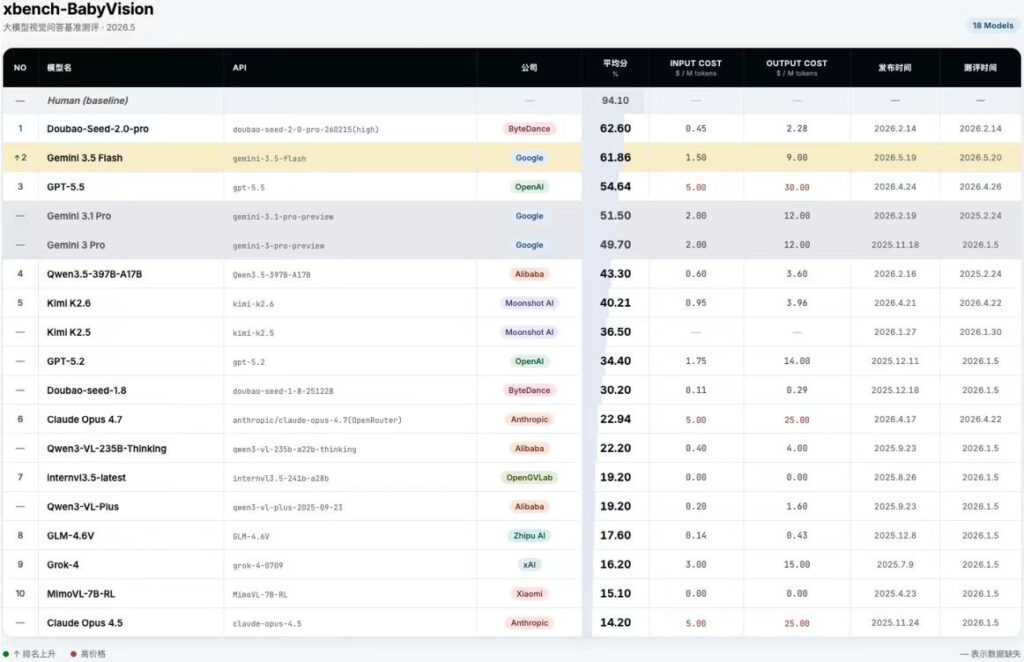
- Gemini3.5 Flash在BabyVision榜单位列第二,仅次于Doubao Seed2.0 pro,优于GPT5.5与Gemini3.1 pro。
- Gemini3.5 Flash在能力和性价比方面均优于国外其他主流模型。虽然对比Doubao Seed2.0 pro,Gemini3.5 Flash的得分略低,同时价格也并不占优,但是对比GPT5.5和Gemini3.1 pro,3.5 Flash模型在得分和性价比方面都是更优秀的。
OneMillion-Bench Leaderboard更新
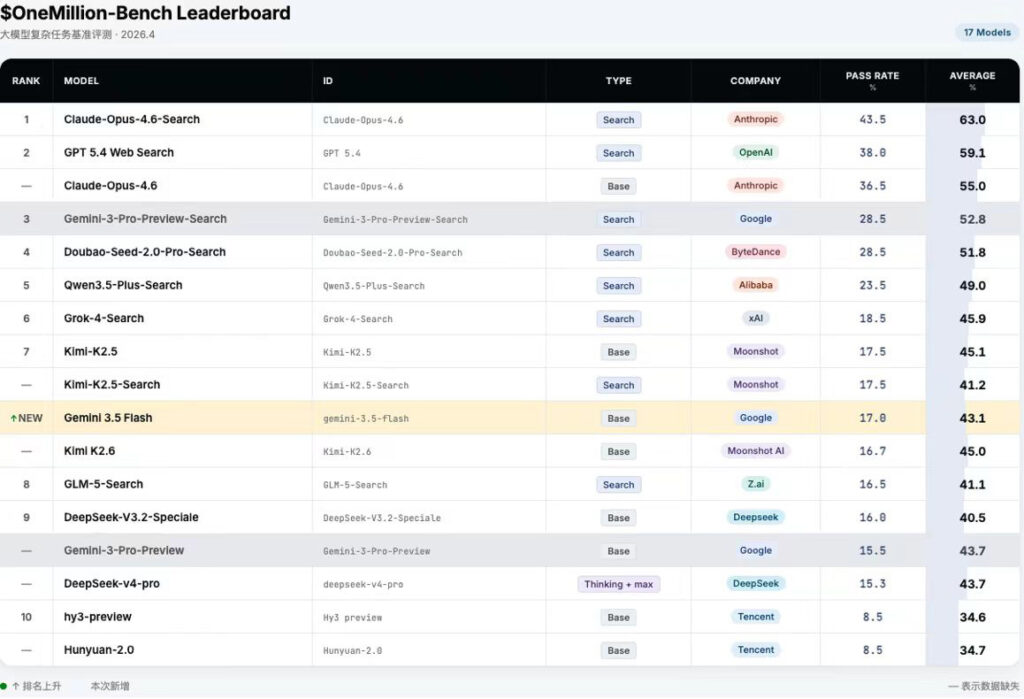
Gemini3.5 Flash
Gemini3.5 Flash是Google针对agent时代推出的高并发、低延迟Frontier模型,核心定位是在保持极致速度与高性价比的同时,下放旗舰级的智能体(Agentic)与编程执行力。专为快速迭代的agentic loop设计,在长周期、复杂repo的多轮代码调试与子智能体部署中,提供不输旗舰大模型的交付质量。同时,相较于同级别旗舰模型,其有4倍的高吞吐、超低延迟以及更具优势的API价格。
- Agentic execution栈被进一步前置,用最低价位的Flash模型跑完整agent loop成为现实。Gemini3.5 Flash把此前pro版本才有的long-horizon planning、tool calling、parallel agent execution下放到Flash层级。在xbench的实测中,在ScienceQA的复杂推理任务中,3.5 Flash用极低的成本,达到头部梯队的分数;BabyVision视觉任务上3.5 Flash直接以61.86的平均分大幅领先 Gemini 3 Pro的49.70。
- Dynamic Thinking默认开启3.5Flash默认开启动态推理预算分配,可以根据任务复杂度自动调节思考长度。这与OpenAI/Anthropic对thinking token的精细控制策略有所不同:Anthropic的路线分歧明显:OpenAI的o-series和GPT-5.x让开发者直接设置推理深度,Anthropic的Opus4.7有thinking budget,可以在agent loop里被task budget进一步约束。
- 3.5 Flash的发布同步配的是Antigravity2.0。这次的更新点有三个。(1)新增CLI,把agent能力搬到命令行,直接对位Codex CLI和Claude Code。(2)新增SDK,开发者可以把Antigravity的agent loop嵌进自己的服务,不再只能在Antigravity IDE里跑。(3)最后是Managed Execution,Google托管的agent运行时支持并行子agent编排,一个主agent fan out到多个子任务的形态,
- 仍缺席的能力Computer Use:值得注意的是,Gemini3.5 Flash本次未携带Computer Use能力,仍需调用单独的Gemini2.5 Computer Use模型。这与Anthropic把computer use整合进Opus4.7主模型的路线形成对比。
Gemini Omni:从”理解多模态”到”生成多模态”
Gemini Omni是Google本次发布的另一条关键路线,定位为any-to-any原生多模态生成模型:用户可以同时输入图像、音频、视频与文本,模型不是把这些素材拼接起来,而是在一个统一的表征空间内跨模态推理后再生成视频/图像输出。首发版本Gemini Omni Flash面向消费级用户,可生成10秒视频。
- 统一表征而非桥接:与”文本预训练后再外挂视觉/听觉编码器”的方案不同,Omni从预训练阶段就让多模态共同演化。这呼应了我们在4月月报中提出的判断——视觉正在从”补丁”变成模型推理链条的原生组成部分。
- 物理一致性与世界知识:官方demo强调Omni在物理、文化、历史、科学等维度的世界知识,是对Veo此前主打”视觉质量”的明显进阶。
- 首版限制:10秒时长、消费级渠道优先、API延后发布。Google同时宣布将推出Omni Pro,但暂未给出时间表。
- 可追溯性:所有Omni生成内容自带SynthID水印;涉及Avatar生成需身份验证。
Omni的发布对当前多模态生成赛道的影响在于:原先在视频生成上各家分别拥有的能力(Sora-2、Veo、Pika、Runway、Kling等),将被Google以一个统一any-to-any接口重新整合进Gemini产品线,且首发即接入YouTube Shorts这种亿级日活分发渠道。