Claude Opus 4.8登顶ScienceQA|xbench 快报
北京时间2026年5月29日,Anthropic发布新一代旗舰模型Claude Opus 4.8。Opus 4.8是Opus 4.7的升级版,定位是在保持价格不变的前提下,提供跨基准的全面提升与更可靠的工作质量。官方同时预告Mythos级模型将在数周内陆续向客户开放。
在Opus 4.8的官方公开评测中,Anthropic称其在agentic coding、跨学科推理、agentic computer use、知识工作与agentic金融分析等方向较Opus 4.7全面提升,computer use在Online-Mind2Web上达到84%。与此同时,Anthropic将模型诚实度(honesty)作为本代重点优化方向:模型在发现自身代码存在缺陷时选择隐瞒或未主动指出问题的概率,已降至上一代的约1/4。
在xbench的榜单中,Claude Opus 4.8以76.4的平均分登顶ScienceQA,且性价比很高。较GPT-5.5 Pro与上一代Opus 4.7(同为73.0)高3.4分,且跑完500题仅花费$25.6,约为GPT-5.5 Pro($471.1)的1/18。但视觉理解仍是它的短板,在 BabyVision上以23.45%分数位列中游。
ScienceQA Leaderboard更新
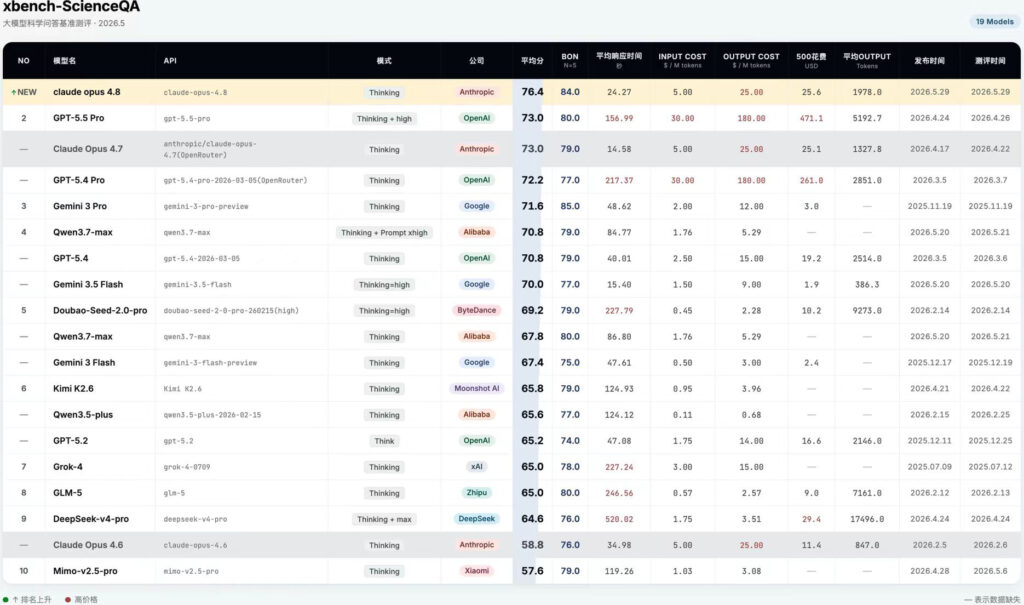
- Claude Opus 4.8以76.4的平均分登顶ScienceQA:是榜单上第一个突破75分的模型。较并列前位的GPT-5.5 Pro与上一代Opus 4.7(同为73.0)高3.4分,较Gemini 3 Pro(71.6)高4.8分,较国内最强的Qwen3.7-max(70.8)领先5.6 分。
- Claude Opus 4.8的性价比远高于第二名GPT 5.5 pro:Opus 4.8跑完500题 Opus 4.8花费$25.6、单题响应24.27秒,而GPT-5.5 Pro要$471.1、156.99 秒。Claude Opus 4.8便宜约18倍、快约6.5倍。
Claude Opus模型ScienceQA分数趋势
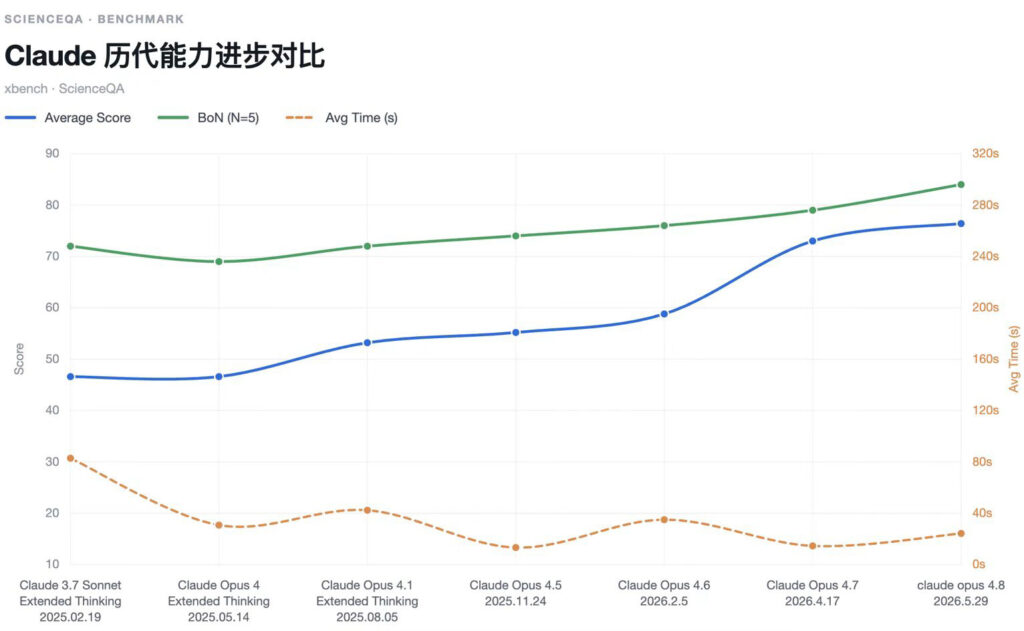
- 在一年时间里,Claude的知识和推理能力提升明显。从Claude 3.7 Sonnet的46.6到Opus 4.8的76.4,把ScienceQA平均分抬高了近30分。提升分布并不平均,Opus 4.6到4.7单代跳涨14.2分,是整条曲线的拐点,其余各代多为个位数推进。
- 平均分与BoN的分差收窄,模型稳定性提升。两者差距从Claude 3.7 Sonnet的25.4分差收窄到Claude Opus 4.8的7.6分差,模型不再靠「五次里挑中一次」,而是单次作答就能稳定逼近上限;稳定性是峰值分数外,能体现模型能力的一个重要维度。
- 在模型平均分不断上升的情况下,推理速度一直保持在的较快的水平。除最早的3.7Sonnet(82.85秒)偏慢,此后各代都在13到40秒之间较为一致,均做了较好的推理效率和Token消耗的优化。
BabyVision Leaderboard更新
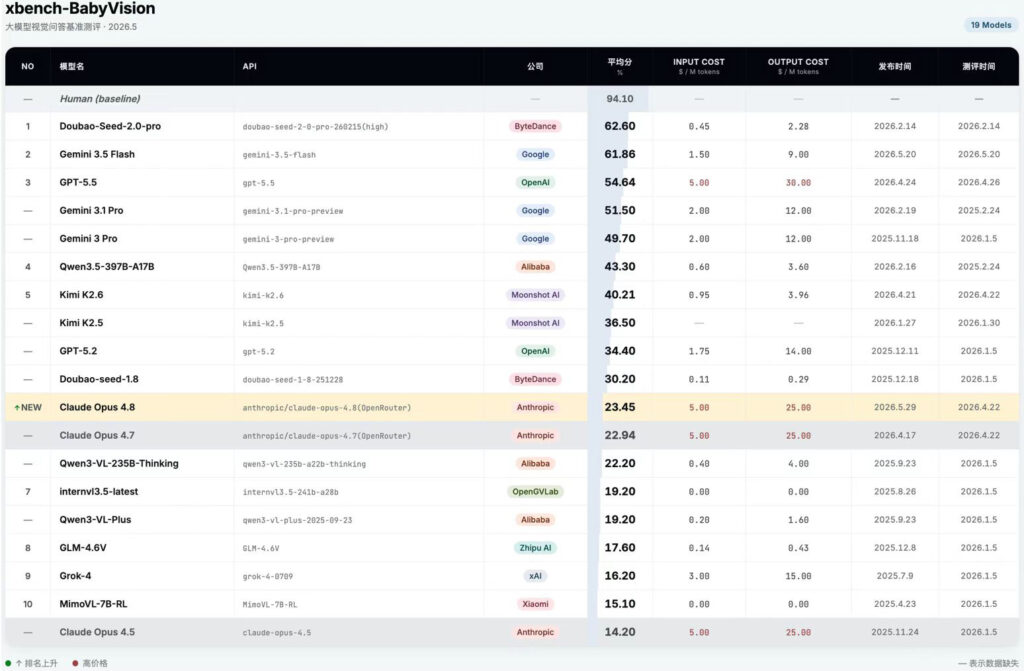
- 视觉理解仍是Anthropic的短板,Claude Opus 4.8以23.45%排在榜单中游。距榜首Doubao-Seed-2.0-pro(62.60%)差39.15分,也大幅落后于Gemini 3.5 Flash(61.86%)与GPT-5.5(54.64%)。
Claude Opus模型BabyVision分数趋势
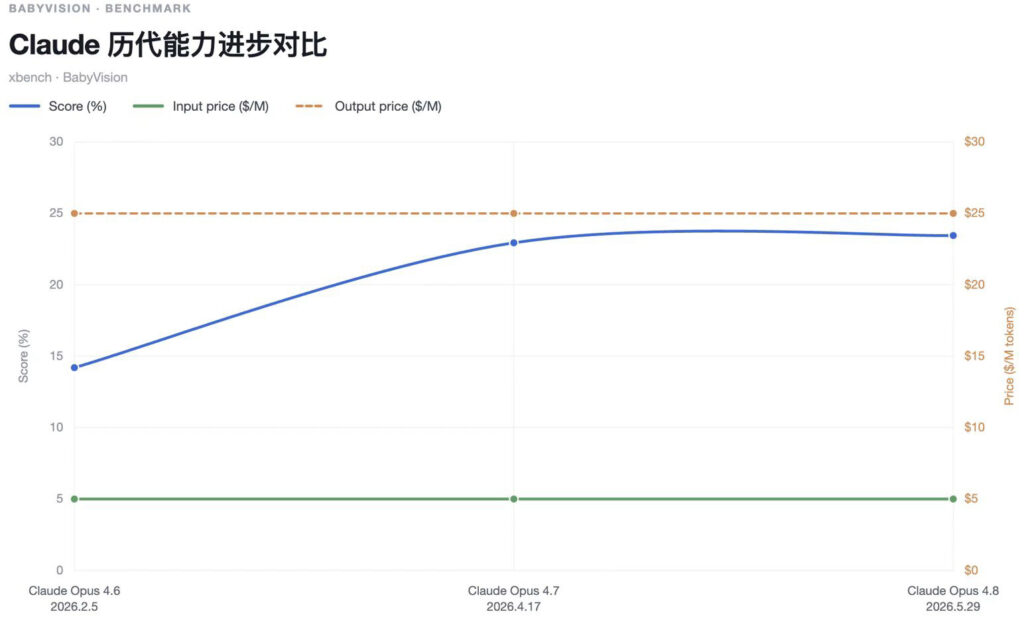
- 视觉能力较自家上一代仅微增。Opus 4.8(23.45%)较Opus 4.7(22.94%)提升0.51分,较Opus 4.5(14.20%)提升9.25分。Claude Opus的视觉理解与视觉推理能力仍在持续提升,但相较于OpenAI GPT-4o与Gemini系列,其多模态能力并非当前主要竞争优势。
Claude Opus 4.8:定位与技术看点
Claude Opus 4.8是Anthropic面向复杂推理与长程agentic任务的旗舰模型,本代核心是以相同价格换取跨基准的全面提升与更高的工作可靠性。标准定价维持 $5/M输入、$25/M输出不变,fast mode则以2.5×速度运行、价格较上代fast mode降到约1/3($10/M输入、$50/M输出);API模型名为claude-opus-4-8。
- Effort控制成为默认入口,按需加码:模型选择器旁新增effort档位,默认 high,可上调extra(或max以多花token换更优结果;high档在编程任务上的 token消耗与Opus4.7默认相近、但表现更好。这与OpenAI让开发者直接设推理深度、Google的Dynamic Thinking自动分配是同一条思考预算可控路线,Anthropic的做法是把默认档调到high并保持与上一代相近的token开销。
- Dynamic workflows:单session跑数百并行子agent:Claude Code新增dynamic workflows(research preview,面向Enterprise/Team/Max),可先规划任务、再在单个session内运行数百个并行子agent,自检输出后回报,已能完成跨数十万行代码的codebase级迁移,以现有测试套件为验收标准。
- 诚实度成为本代重点升级:Opus 4.8更倾向标注不确定、减少无依据断言;官方评测显示其放任自身代码缺陷不被指出的概率约为上一代的1/4,把可靠性而非单纯分数作为卖点。
- Computer use进一步整合进主模型:本代强化agentic computer use,官方公布Online-Mind2Web达到84%,延续Anthropic把computer use内置进主模型、而非拆成独立模型的路线。
Opus 4.8这次的信号是同价提质:在定价、推理token路线都不变的情况下,Anthropic把升级重心放到了agentic规模(数百并行子agent、codebase级迁移)与工作可靠性(诚实度提升4倍)上,而不是堆叠跑分。叠加数周内将推出的 Mythos级模型预告,Anthropic在agentic coding赛道上的节奏是先把旗舰做稳、再向上拉代际。
落到xbench实测,Opus 4.8的进步集中在它本就擅长的推理与agentic方向:它登顶了ScienceQA,而在BabyVision代表的视觉任务上仍明显落后于头部模型。Anthropic这一代延续了推理强、视觉弱的整体格局,把提升放在了优势项上。
xbench是红杉中国推出的一款全新的AI基准测试工具。xbench采用双轨评估体系,构建多维度测评数据集,旨在同时追踪模型的理论能力上限与Agent的实际落地价值。并采用长青评估的机制,通过持续维护并动态更新测试内容,以确保时效性和相关性。
联系方式:team@xbench.org