新模型组团出道,多项机器人技术开源,近期AI新鲜事还有这些……

AI最前沿,速递科技奇点,一起聚焦近期全球AI新鲜事。本期,我们带来了以下内容:
- AI科研发现自动化正在成真
- OpenAI 开发者大会
- 混元图像3.0登顶LMArena榜单
- 多项机器人关键技术开源
- 智谱GLM-4.6 Coding能力创新高
- 最强代码模型Claude Sonnet 4.5来了!
- DeepMind新论文:Veo 3“无师自通”
AI科研发现自动化正在成真
近年来,大语言模型(LLM)的出现推动了自动化科学发现的发展。基于LLM的AI科学家(AI Scientist)系统在探索中处于领先地位,凭借强大的长篇文本生成能力和理解能力,LLM实现了科学发现的端到端、全周期自动化。
但是,在缺乏明确科学目标的情况下,当前的AI科学家系统往往陷入盲目重组现有知识和方法的陷阱。因此,AI科学家所做出的研究成果,在人类科学家看来,仍然很幼稚,往往缺乏真正的科学价值。
而现在,人类科学家三年累计取得的进展,一个AI科学家竟然短短两周搞定!
西湖大学开发的一款AI科学家系统——DeepScientist,在AI文本检测任务中,短短两周就取得了相当于人类三年的研究进展,并在智能体失败归因、LLM 推理加速、AI文本检测等领域全面刷新纪录。更关键的是,整个科研过程除目标设定外无需人工干预,实现了人类出题、AI自主挑战的闭环。它成为首个大规模实证研究证明的能够在前沿科学任务上渐进式超越人类科学家最先进水平(SOTA)的AI科学家系统。
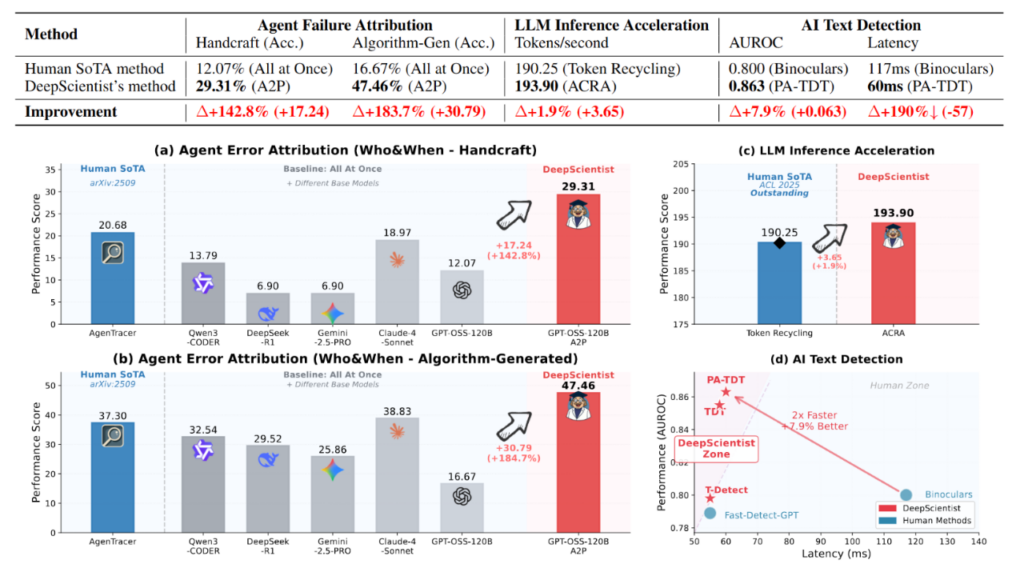
在研究团队看来,AI就是不知疲倦的科学探索引擎,这一突破或将开启科学发现自动化的更大探索空间。
OpenAI开发者大会:新工具新模型组团出道
近日,OpenAI在旧金山举办了规模空前的开发者大会,现场约有1500名全球开发者参加,线上观众更是突破数万。
OpenAI在会上晒出了近两年成绩单:平台已聚集400万开发者,ChatGPT周活跃用户达8亿,API每分钟token处理量近60亿。同时,大会发布多款AI开发工具,全新推出的Apps SDK让ChatGPT从对话工具变身应用平台;全能工具集AgentKit助力开发者从原型快速落地,软件工程代理工具Codex也推出正式版。
此外,模型层面也迎来一系列更新。Sora 2的API开放最为引人注目。相比初代,10月1日刚刚发布的Sora 2在物理规律呈现、提示一致性上显著提升,生成内容更准确逼真,且能实现同步对话和音效功能,甚至可直接将现实世界的元素注入生成内容中。OpenAI还同时推出了由Sora 2驱动的Sora App。在应用中,用户可以创建音视频生成内容、还能在可定制的信息流中“刷视频”,并通过“客串”功能将自己或朋友带入视频。
新模型、新工具、新生态。从模型提供商到平台构建者,OpenAI正不断拓展自己的边界。
LMArena榜单更新,混元图像3.0登顶
10月初,文生图领域的“权威竞技场”LMArena放榜——发布仅一周的混元图3.0,从全球26个大模型里突围,登顶第一。
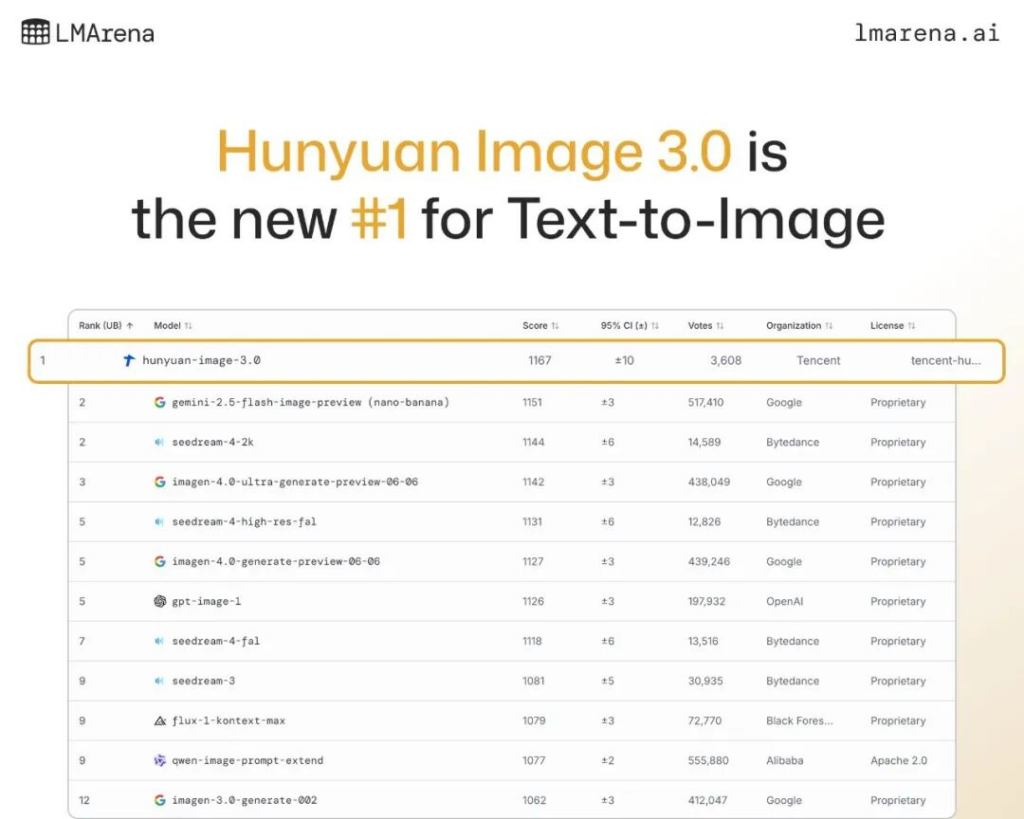
作为业界首个开源工业级原生多模态生图模型,混元图像3.0的性能直接对标闭源模型,且刷新了开源AI生图模型的SOTA。它也是目前参数量最大的开源生图模型,参数规模达800亿,拥有64个专家网络,具备世界知识推理、极致美学表现、精确文字生成等核心能力。
机器人学习大会:多项关键技术开源
近日,英伟达在机器人学习大会(CoRL)上开源物理引擎Newton、推理模型Isaac GR00T N1.6和世界模型Cosmos等多项技术,旨在解决机器人研发中的仿真、推理和训练难题。
这也是一次完整的机器人开发生态的发布会。其中,物理引擎Newton负责精准模拟机器人身体,能精确仿真复杂动作和环境,已获顶尖机器人公司与高校率先应用;推理模型GR00T赋予机器人思考能力,能理解模糊指令并利用常识制定执行计划,模型同时具备数据标注能力,可筛选合成训练数据;世界模型Cosmos则提供海量训练数据,让数据生成效率大幅提升——开发者通过文本、图像和视频提示,就能生成多样化训练数据——这意味着机器人训练所需的海量数据不再依赖昂贵且耗时的真实世界采集,合成数据即可满足大部分需求。
从物理引擎到基础模型等一系列工具的开源,有望显著缩短机器人开发周期,加速技术落地。
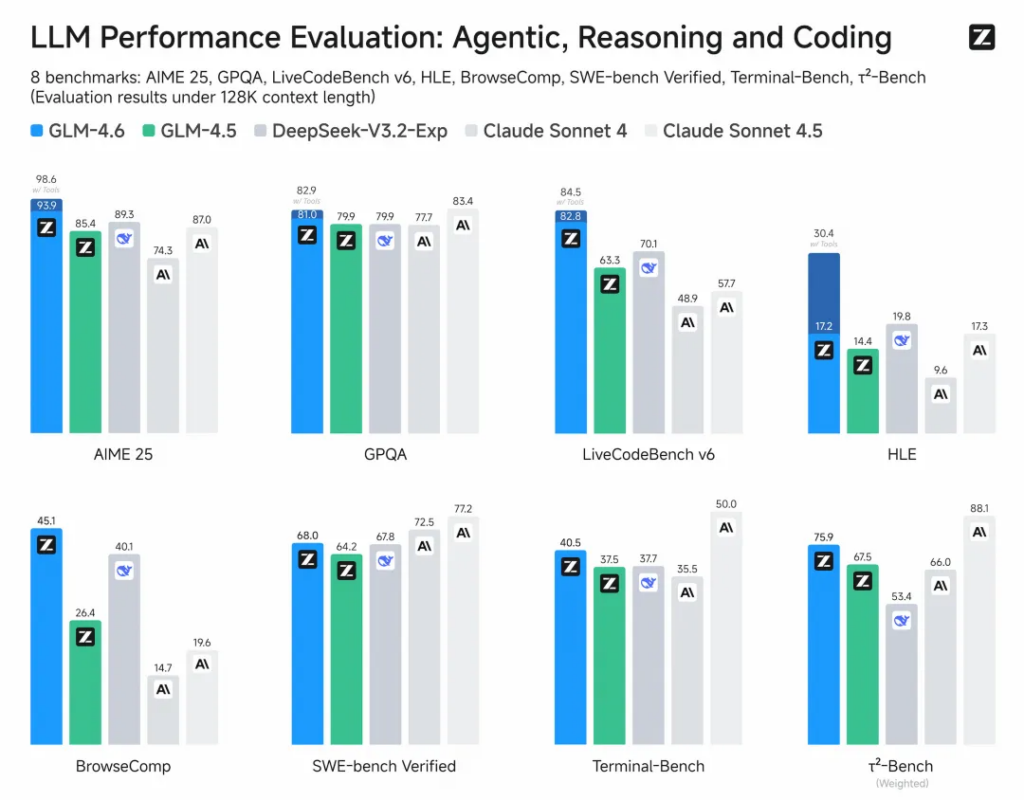
智谱GLM-4.6上线,Coding能力创新高
智谱正式发布并开源了新一代人工智能大模型GLM-4.6。作为GLM系列的最新版本,这款模型在架构上展现了显著的技术进步。
GLM-4.6模型总参数量达到355B,激活参数为32B,在保持高效推理的同时实现了性能的全面提升。
模型的核心升级之一是它上下文窗口从128K大幅扩展至200K token,能够处理更复杂的智能体任务和更庞大的文档。
在token效率方面,GLM-4.6实现了超过30%的提升,在平均token消耗上比GLM-4.5节省30%以上,为同类模型最低,这意味着用户可以在相同预算下处理更多的任务。
在代码能力上,较GLM-4.5提升27%。在公开基准与真实编程任务中,代码能力已对齐Claude Sonnet 4,是目前国内最强的Coding模型,其整体性能超过了前一天发布的DeepSeek-V3.2-Exp。
除了代码能力,GLM-4.6在推理能力、信息搜索、写作能力与智能体应用等多个方面也实现全面提升。同时,还支持在推理过程中调用工具,增强了模型在工具调用和搜索智能体上的表现。
新王者!最强代码模型Claude Sonnet 4.5来了
Anthropic正式发布Claude Sonnet 4.5,它不仅具备高准确率,还能在复杂多步骤任务中保持超过30小时的专注执行,长时稳定性远超前代模型。此外,该模型在智能体构建、推理和数学能力上也有显著突破。

Claude 4.5的核心武器是代码能力。在衡量真实世界编程能力的权威基准SWE-bench Verified上,Sonnet 4.5取得了82.0%的准确率,超过了其前代Opus 4.1(79.4%),也领先GPT-5(72.8%)和Gemini 2.5 Pro(67.2%)。这让它在软件工程领域站上了新的高点。
除了各种性能外,Anthropic还重点强调了Claude Sonnet 4.5的对齐和安全性指标。通过安全训练,Claude Sonnet 4.5减少了谄媚、欺骗等不良行为;在智能体和计算机场景下,Claude Sonnet 4.5在防御即时注入攻击方面也取得了显著进展。同时,针对正常内容的误报也有所降低,正常请求拒绝率从Sonnet 4时的0.15%下降到了0.02%。
除了发布模型更新,Anthropic还官宣了Claude Agent SDK,可以帮助开发者基于Claude Code构建智能体。
DeepMind新论文:视觉模型也“通才”
DeepMind研究团队发现,它们最新的视频模型Veo 3已经学会了“无师自通”,给它一张图、一句话,它就能处理一堆以前压根没学过的视觉任务。
相关论文《视频模型是零样本学习者和推理者》(Video models are zero-shot learners and reasoners)中表示,研究人员发现,视频模型正在成为计算机视觉领域的那个“通才”,就像大型语言模型(LLMs)统一了自然语言处理(NLP)领域一样。
研究者将其学习能力按感知、建模、操纵、推理四层递进结构拆解,并实例展示了视频模型如何通过类似大语言模型“思维链”的“帧链”能力,在零样本学习的情况下解决复杂的视觉推理任务。
推理测试:在一系列操纵步骤中,跨越时间和空间进行规划和解决问题。
视频提示词:在不越过任何黑色边界的情况下,角落里的那只灰色老鼠熟练地在迷宫中四处游走,直到找到那块黄色的奶酪。
综合来看,传统的计算机视觉任务,比如边缘检测、物体分割、关键点定位,都需要专门的模型来处理,但Veo 3不需要任何针对性训练,就可以做到。它还能做超分辨率、图像去模糊、去噪和低光增强。
这些能力甚至延伸到更复杂的任务上,比如在一堆东西里找出你要找的(联合搜索),或者看懂那些模棱两可的图片。除了去噪本身就是扩散模型的老本行,其他技能在视频模型上几乎都没有被刻意训练过。
而且,在感知的基础上,Veo 3还开始对世界进行建模。它似乎理解一些朴素的物理规律,例如刚体和软体、空气阻力和浮力、光的折射和反射等等。此外 ,Veo 3还能理解一些抽象关系,例如它能分清玩具和笔记本电脑的区别。
它对三维世界的理解也让人惊讶,而且还能处理复杂的互动指令,例如演示如何画一个形状。总而言之,视频模型正在有目的地操纵和模拟一个数字化的视觉世界,而且研究人员还在很多任务中看到了其推理能力的萌芽。
Veo 3涌现的零样本能力表明,视频模型有望像大语言模型一样,发展为视觉基础模型。
综合来看,传统的计算机视觉任务,比如边缘检测、物体分割、关键点定位,都需要专门的模型来处理,但Veo 3不需要任何针对性训练,就可以做到。它还能做超分辨率、图像去模糊、去噪和低光增强。
这些能力甚至延伸到更复杂的任务上,比如在一堆东西里找出你要找的(联合搜索),或者看懂那些模棱两可的图片。除了去噪本身就是扩散模型的老本行,其他技能在视频模型上几乎都没有被刻意训练过。
而且,在感知的基础上,Veo 3还开始对世界进行建模。它似乎理解一些朴素的物理规律,例如刚体和软体、空气阻力和浮力、光的折射和反射等等。此外 ,Veo 3还能理解一些抽象关系,例如它能分清玩具和笔记本电脑的区别。
它对三维世界的理解也让人惊讶,而且还能处理复杂的互动指令,例如演示如何画一个形状。总而言之,视频模型正在有目的地操纵和模拟一个数字化的视觉世界,而且研究人员还在很多任务中看到了其推理能力的萌芽。
Veo 3涌现的零样本能力表明,视频模型有望像大语言模型一样,发展为视觉基础模型。