Auto Research时代,AI Scientist的第一场药企实习考验

过去一年,AI Scientist从只会乖巧答题的大模型做题家,快速进化为自动化科研助手(Auto research):它可以自己提假设、查文献、写代码、跑实验、分析结果,甚至连论文都帮你写好。但从demo到应用,AI scientist领域正面临一个亟待解答的问题:AI做科研的时代已来,但谁会为它的研究买单?
这一次,我们把这个问题放进最难的行业场景之一:生物医药。
xbench联合Phylo、Humanlaya Data Lab团队,汇聚斯坦福、哈佛、北大和头部药企的100位资深专家,耗时1000余小时,共同构建了全球首个面向真实生物医药研究场景的过程级评估框架——BiomniBench,并让AI从头到尾做一遍药企的真实数据分析(BiomniBench-DA)。
经过评估,这些“AI scientist实习生”的表现如下:
- 最强AI scientist实习生拿到73.34分(满分100),显著高于人类实习生40-50分的平均线。
- 除基础模型外,智能体框架(Agent Harness)对结果的影响也很大。同一个GPT-5.4,放在Codex CLI里68.69分,放在Terminus-2里只有55.19分。差了13.5分。
- AI scientist更快更省,单个任务平均用时4.9-25分钟、花0.92-4.58美元,而人类完成同样的任务通常需要数小时甚至数十小时。
- AI scientist也偏科,不同任务类型之间的表现差距显著。
AI scientist实习生到底被派去做什么?
在药企,搞研究可不是那么简单——
比如:给你一组免疫治疗患者的单细胞测序数据和临床信息,你要判断某个 biomarker(生物标志物)是否值得进入下一轮实验验证。这听起来并不复杂,但实际要面对的是:数据清洗、样本筛选、统计方法、多重检验校正、生物学解释…
每一步都可能出错。
而“在生物学里,一个看似正确的结论可能建立在完全错误的分析过程之上——而等你发现的时候,药已经做失败了。”这句来自药企一线科学家的提示,为我们指向了一个关键问题:评价一个AI Scientist是否能胜任药企的工作,不能只看结果,还需要关注整个过程。
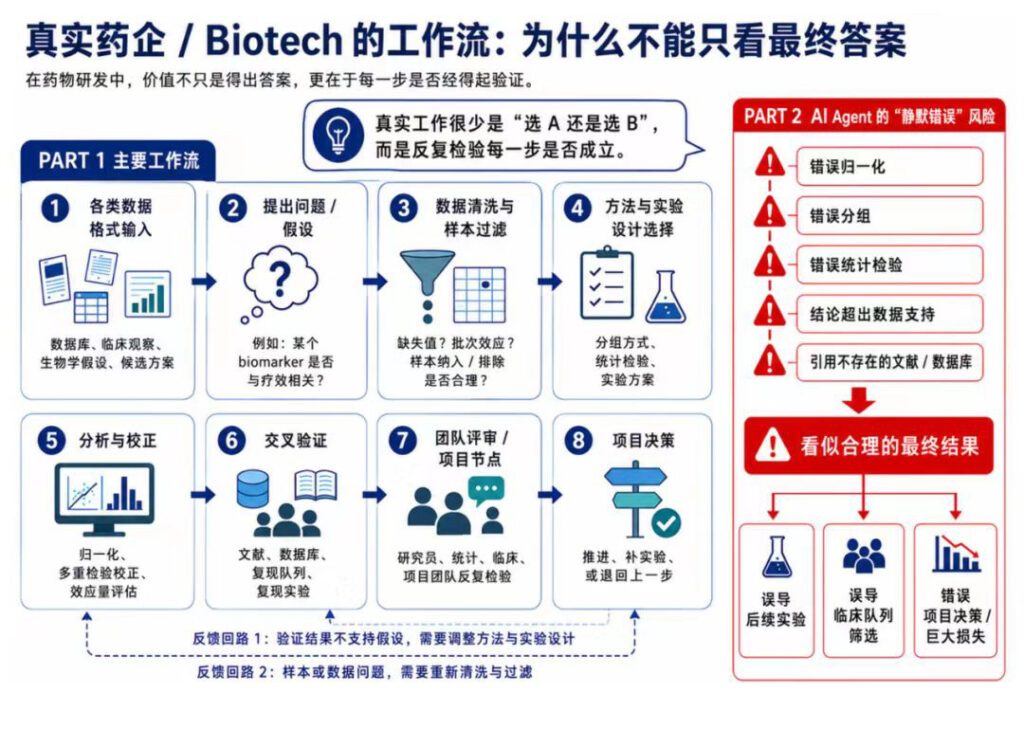
真实情况:跑通了不等于做对了
过去一段时间,AI Scientist领域出现了大量Benchmark,他们试图帮助我们衡量模型是否知道某篇论文、某种方法、某个基因,以及能否在知识问答中给出正确答案。
但这些benchmark几乎都只在评答案对不对。
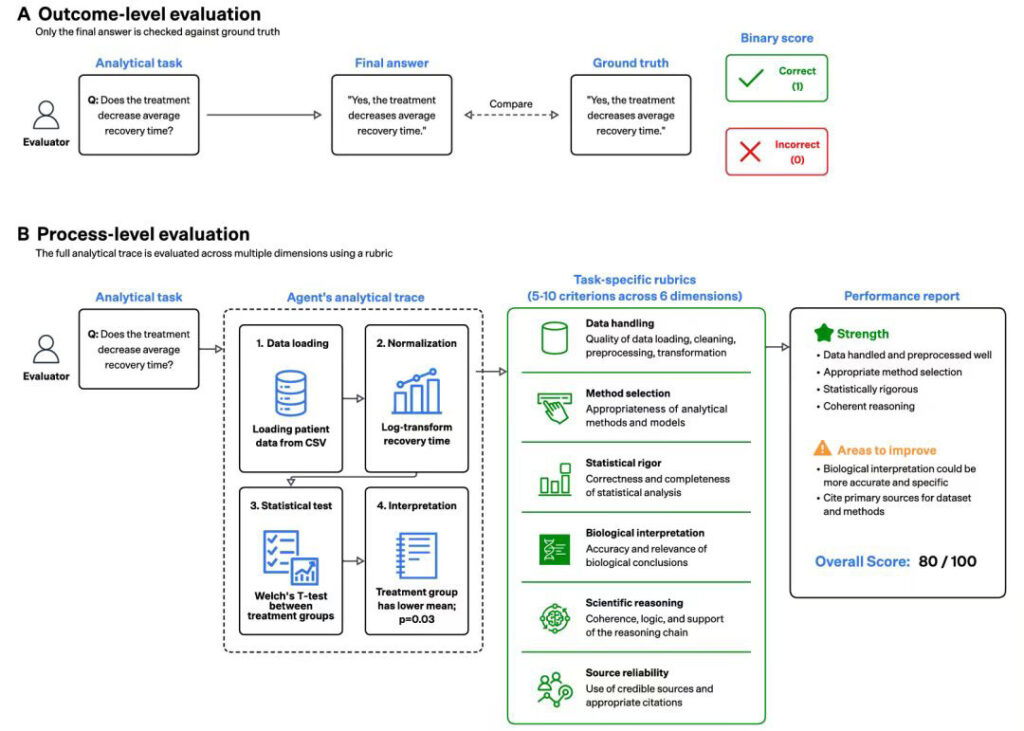
xbench本次推出BiomniBench,旨在从根本上扭转当下benchmark的不足,不仅关注任务的结果,更关注测试是「模型会不会真的做研究」,从数据清洗、到方法选择、到统计检验、到生物学解释,每一步都测。达到了Agent测试的更深一步:process-level evaluation,过程级评测。
首个考核任务-生物医药数据分析
我们聚焦AI scientist在生物医学研究中最常见、也最贴近真实研发流程的使用场景——数据分析任务,推出首个落地评测模块:BiomniBench-DA。
这套Benchmark共100道题目,结合Nature、Cell、Science等高影响力论文的公开数据,由原论文作者或拥有5年以上行业经验的专家联合出题,把真实工作中常见的干扰因素和决策逻辑融入每一道题中,全面覆盖生物医药研究的5大疾病领域,和17类核心分析任务。
在测试的过程中,AI答题需要给出完整分析轨迹,包括:读了什么数据,做了哪些清洗,为什么选某个方法,统计结果怎么样,怎么解释。然后LLM裁判按专家写好的评分标准(Rubric),从六个维度打分:数据处理、方法选择、统计严谨性、生物学解释、科学推理、来源可靠性。
当然,评分标准允许多条合理路径。很多生物学问题没有唯一答案,关键在于论证清晰、有据可循。Agent不会因选择了与示例分析路径不同,但同样正确的方法而被扣分。
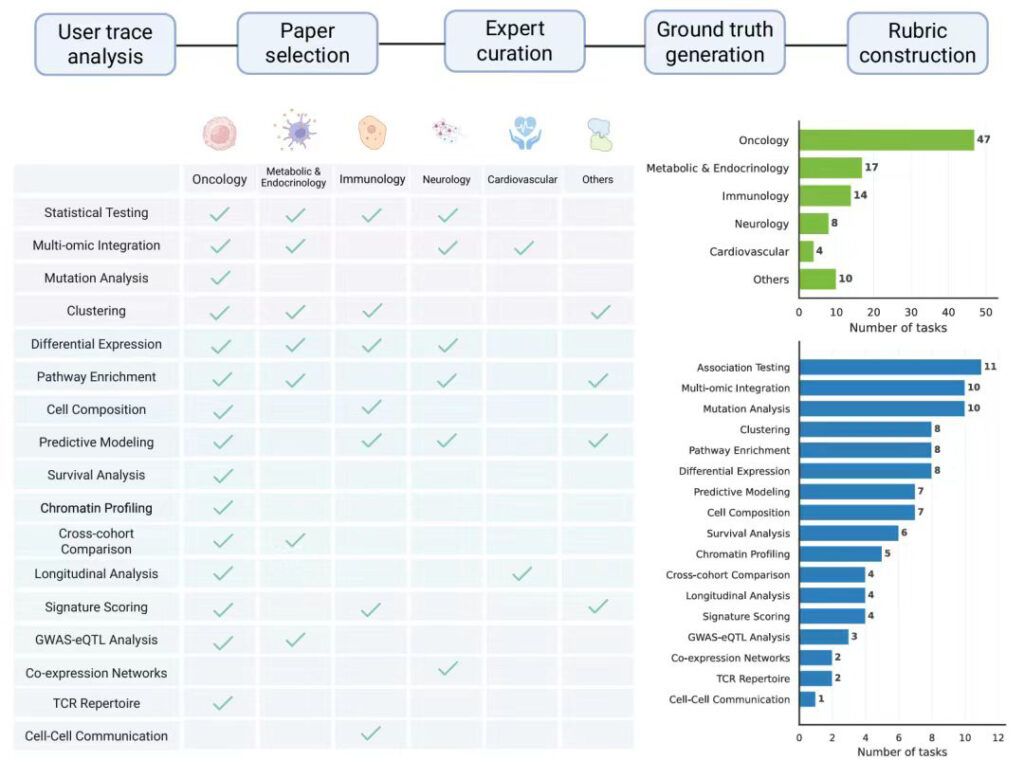
5大疾病领域×17类任务、例题
AI Scientist的药企实习结果
Insight 1 谁是最强AI scientist实习生
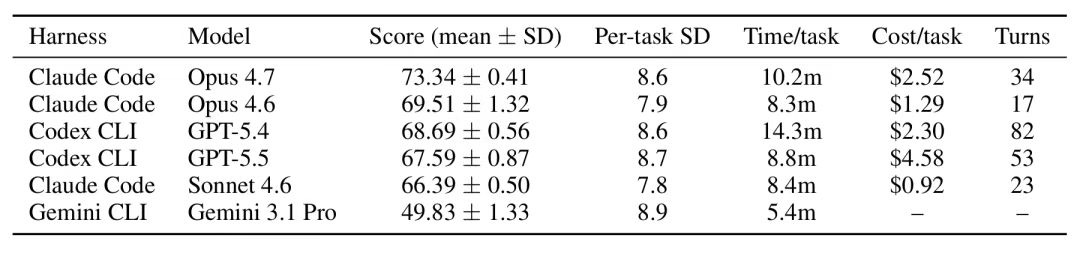
最强配置是Claude Code + Opus 4.7,73.34分。排在后面的是Claude Code+Opus 4.6,69.83分。第三名Codex CLI+GPT-5.4,68.69分。前三名里两个是Claude Code的配置。
作为参照,我们邀请了几位人类实习生在限定时间内作答部分题目,其平均得分在40-50分之间。这意味着最强的AI scientist实习生表现已经超越了人类实习生平均水平。
Insight 2 Agent Harness对结果的影响与基础模型一样重要
在药企数据分析这个场景下,Agent Harness与模型能力对结果提升同等重要。在固定基础模型的情况下,更换Agent Harness会显著改变得分。最明显的案例是GPT-5.4:
- 在Codex CLI 下得分为 68.69;
- 而在Terminus-2下仅为55.19。
这13.5分的差距完全归因于Agent Harness。
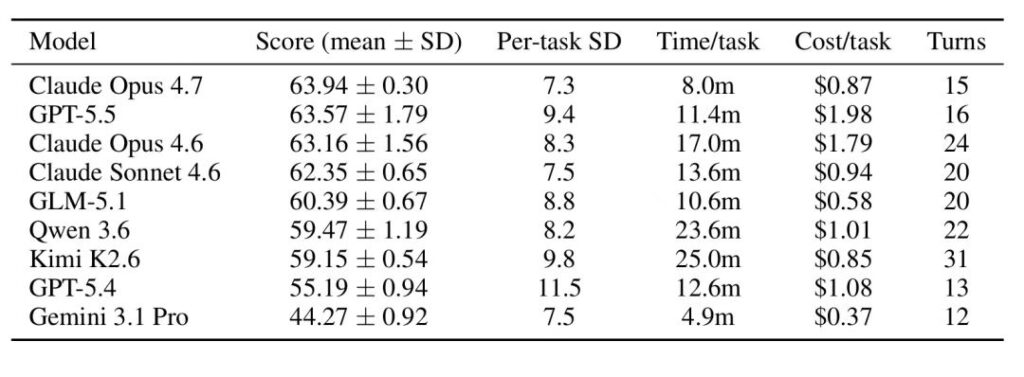
Terminus-2 Agent Harness下9个基础模型的表现
Insight 3 AI Scientist更快更省
AI scientist单个任务平均用时4.9-25分钟,花0.92到4.58美元;而人类完成同样的任务通常需要数小时甚至数十小时。在速度和成本上,AI展现出一贯的优势。
对药企来说,这个进步还是很有价值的:大量探索性分析可以前置、并行化,然后丢给AI,早期试错成本大幅降低。
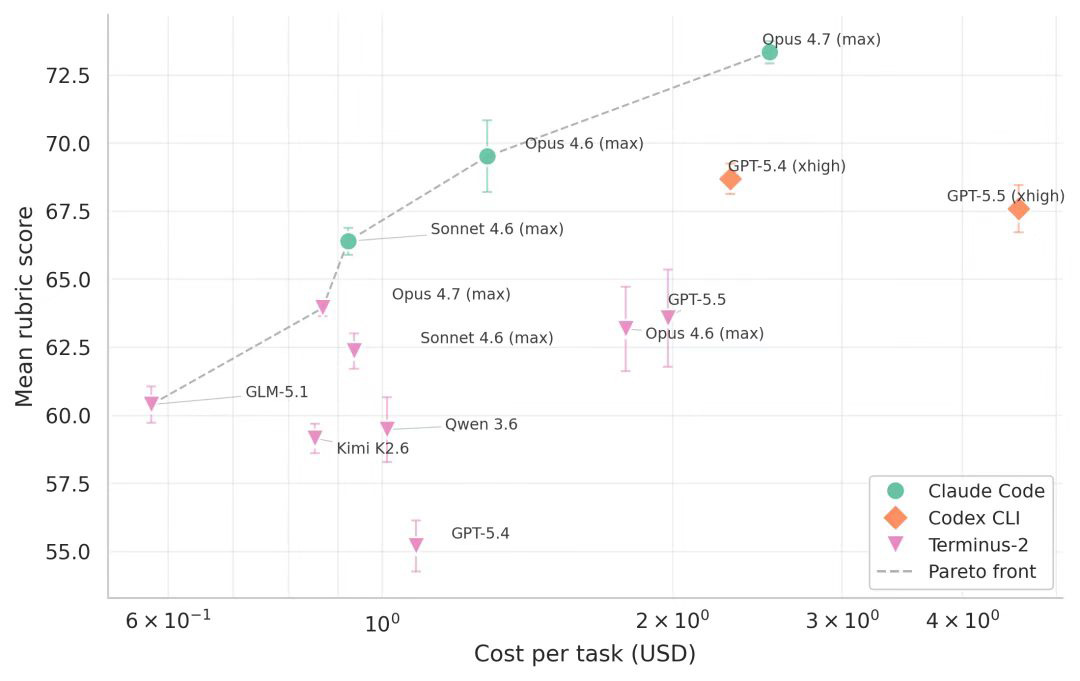
贵的不一定好,但好的确实贵
Insight 4 AI Scientist也“偏科”
AI scientist在不同任务类型之间的表现差距显著。细胞组成分析最高分拿到 91分,突变分析88分。边界清晰的任务是AI的专长。而GWAS-eQTL分析只有 45分,通路富集64分。需要判断统计方法、理解生物学上下文、和重科学推理的任务,AI就稍显乏力了。
可见AI擅长计算,但对结果的生物学意义和科学深度理解还比较有限。短期内「AI算+人类解释」可能是最安全的协作模式。
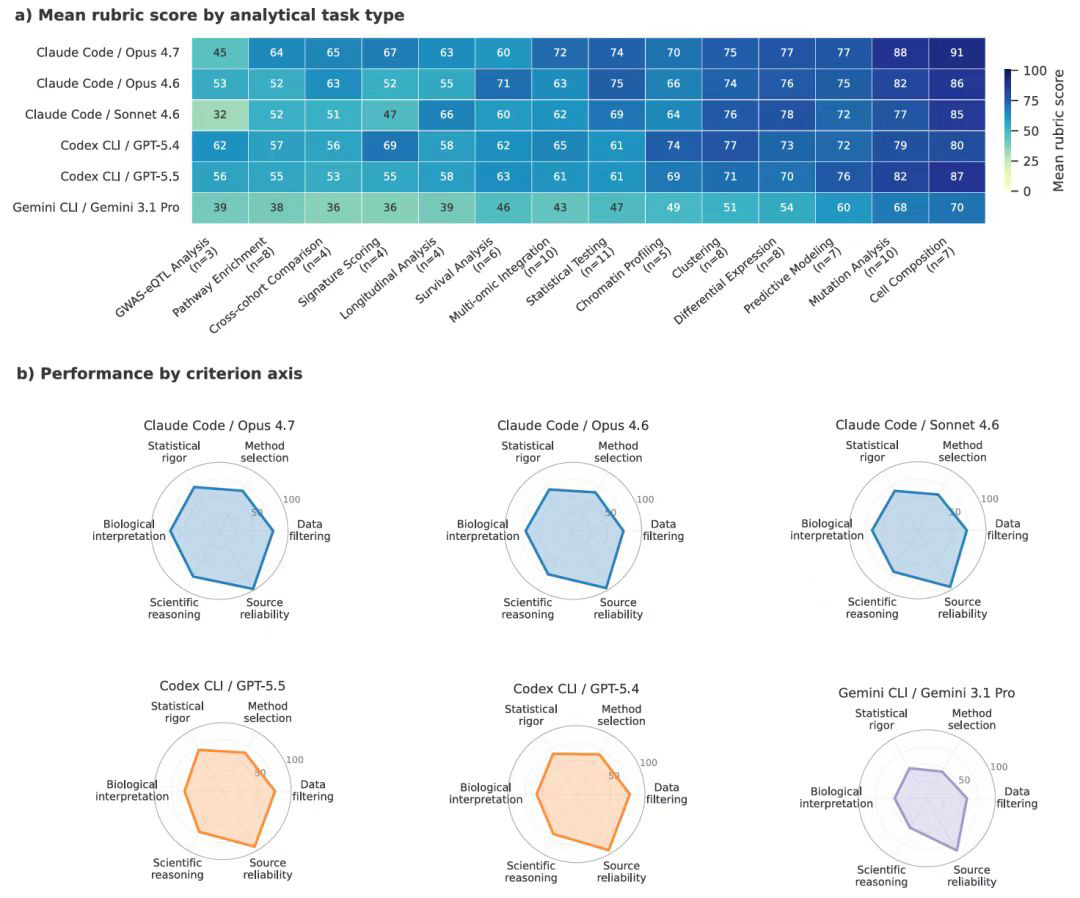
写在最后
过去的benchmark像一场考试,给题、给答案、判对错。而Auto Research 需要的是上岗评测,给数据、给目标、看过程、看结果、看风险。问题的关键不再是“这个模型准不准”,而是“这条分析链条,科学家敢不敢信”。
所以,xbench推出BiomniBench的真正意义,不在于给生物医药AI Scientist 排一个名次,而希望回答一个更大的问题:当AI Scientist试图端到端地自动化科研流程时,我们该如何判断它是否在真的做研究?
AI Scientist的进步,来自基础模型、Agent Harness、行业知识,以及AI研究者与领域专家共同构建的Verification Loop。对AI研究者而言,我们希望为大家打开真实的药企场景视野,了解真实任务中的难点。对生物医药从业者来说,我们也希望提供一个更贴近真实部署、并能客观了解AI现阶段能力的视角。我们相信,当过程被看见、当推理被验证、当每一环都可追溯,AI与科学家之间的信任,才真正开始建立。
所以,实习结束。
如果是这样一位AI Scientist实习生,你会让它转正吗?
本次测评主要聚焦数据分析任务(Data Analysis),生物医药行业拥有极其多元的角色与职能,本次测评结果不代表所有岗位的情况。未来我们将延续这套过程级评测框架,推出覆盖更多行业场景的benchmark。欢迎行业专家、AI researcher联系合作。
本次BiomniBench-DA仅评估了部分模型与Harness组合。未来我们将覆盖更多模型及AI Scientist专业产品。同时,我们将开源部分题目供内部测试使用。如您对产品在全部100道题上的评测结果感兴趣,欢迎联系我们。
我们的联系方式:team@xbench.org
Paper
https://www.biorxiv.org/content/10.64898/2026.05.12.724604v1
Huggingface
https://huggingface.co/datasets/phylobio/BiomniBench-DA
【作者介绍】
xbench是红杉中国推出的一款全新的AI基准测试工具。xbench采用双轨评估体系,构建多维度测评数据集,旨在同时追踪模型的理论能力上限与Agent的实际落地价值。并采用长青评估的机制,通过持续维护并动态更新测试内容,以确保时效性和相关性。
Phylo源自开源项目Biomni,由斯坦福科学家团队于2025年创立,是一家专注于生物医学智能体的应用研究实验室。2026年2月,Phylo 正式推出Biomni Lab——新一代集成生物学环境,致力于让每一位生物医学科学家都能借助AI Agent加速科学发现。
Humanlaya AI是一家成立于2025年的AI数据实验室,通过定义真实、高经济价值的可验证任务,推动大模型能力边界的拓展与经济价值的落地。