Gemini 3 Pro刷新ScienceQA SOTA|xbench快报
北京时间2025年11月19日凌晨,Google正式发布了其最新一代基础模型Gemini 3。Gemini 3在深度推理与思考、多模态理解、Agent编程能力上有极大提升。在xbench-ScienceQA榜单中,Gemini 3 Pro以71.6的平均分超越Grok-4成为新SOTA,并且响应时间快,价格低。
ScienceQA Leaderboard更新
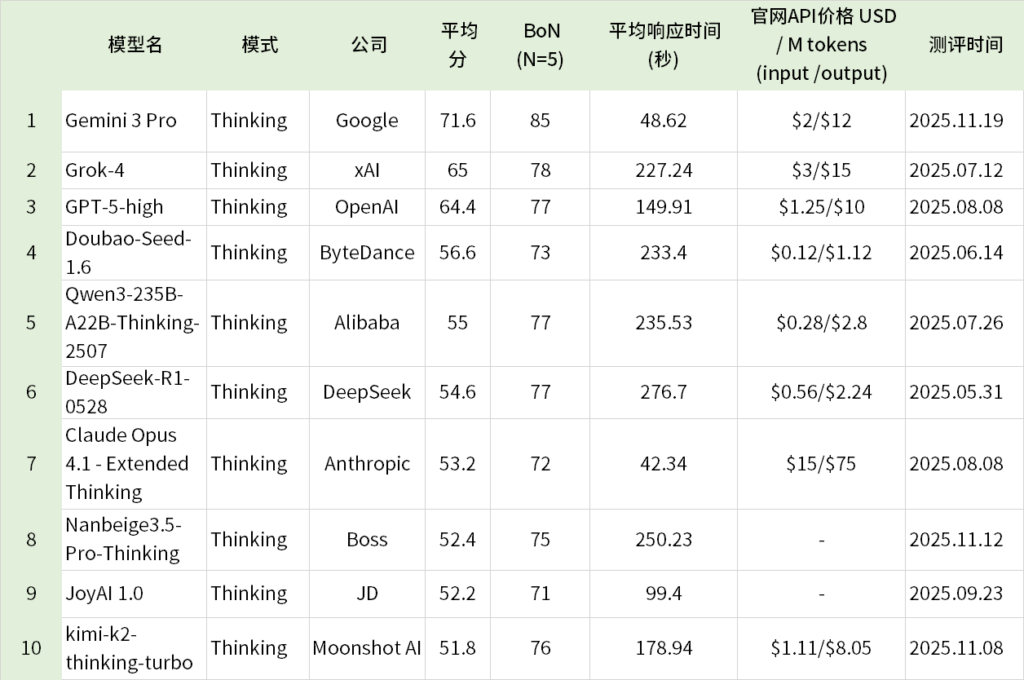
Website: https://xbench.org/agi/scienceqa
xbench采用长青评估机制,持续汇报最新模型的能力表现,更多榜单未来将陆续更新。可以在xbench.org上追踪我们的工作和查看实时更新的Leaderboard榜单排名;欢迎通过team@xbench.org与我们取得联系,反馈意见。
Gemini测评
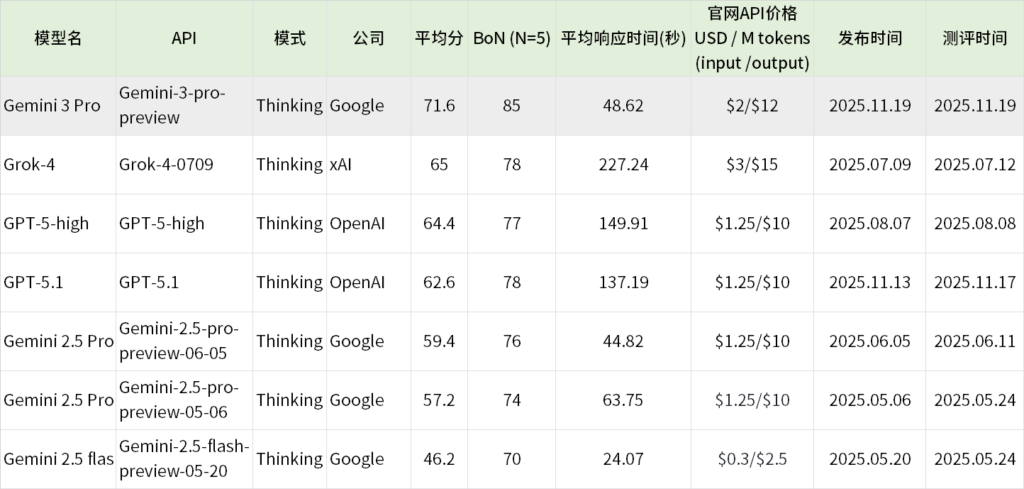
- Gemini 3 Pro与此前Gemini 2.5 Pro相比,平均分从59.4提升到71.6,超过第二名的Grok-4的分数6分。BoN(N=5)达到85分,和其他模型拉开了一定差距。
- Gemini 3 Pro平均处理每道题目的时间仅49s,远快于Grok-4的227s和GPT-5.1的150s。
- 运行同样的任务,Gemini 3 Pro的花费只有GPT-5.1的1/10。根据消耗token数和API费用,粗略统计模型运行完ScienceQA的成本(100×5=500题),GPT-5.1花费是$32,Gemini 3 Pro的花费仅是$3。
Gemini 3的新特性及技术解析
- 认知架构与“深度思考”机制
Gemini 3最本质的飞跃在于其推理由“反应式”向“审慎式”的转变。
不同于以往模型倾向于对提示词进行单纯的模式匹配,Gemini 3引入了类似人类思维的Deep Think(深度思考)模式。在处理高复杂度任务(如数学证明、法律逻辑推演)时,模型不再急于生成首个可行解,而是会在内部构建多条推理链路,进行自我博弈与验证。
这种架构上的调整直接解决了大模型常见的“幻觉”与“阿谀奉承”问题,它不再为了讨好用户而顺从错误的预设,而是基于客观事实进行逻辑反驳。这种深层推理能力使其在xbench-ScienceQA、Humanity’s Last Exam和GPQA Diamond等博士级难度的基准测试中,展现出了甚至超越人类专家的准确性,标志着AI从“知识检索”向“逻辑推理”的真正跨越。
同时,Gemini 3采用了稀疏MoE架构,模型拥有海量参数专家,但每次仅激活一小部分专家参与计算,这意味着在保证性能的同时显著降低计算开销,从而提高训练和推理效率。
- Agent工作流与“氛围编程”
在开发者领域,Gemini 3带来了“Vibe Coding”的概念,并配合Google Antigravity平台将其落地。这代表了代码生成技术从“语法正确”向“意图对齐”的进化。
所谓的“Vibe”是指模型能够捕捉代码库中隐含的工程风格、架构规范以及开发者的模糊直觉。Gemini 3 Pro不仅仅是一个代码补全工具,更是一个自主Agent。它能够在IDE中作为一个独立实体运行,拥有操作终端、浏览器和文件系统的权限。在面对涉及数百个文件的重构或全栈应用搭建时,它具备长程规划能力,能够自主拆解任务、编写代码、运行测试、自我Debug并最终交付。
在Antigravity 中,Google将 Gemini 3 Pro与其它专用模型进行了深度集成。例如,它内置了最新的Gemini 2.5 Computer Use模型用于浏览器自动化操作,以及视觉模型Nano Banana处理图像信息。借助这些组合,开发者可以在统一环境下让智能体读取网页、执行浏览器点击、分析图像,然后调用Gemini 3 Pro进行推理和代码生成,再由终端执行代码并验证结果。整个过程被封装在Antigravity工作流中,开发者只需高层描述任务,AI代理就能“计划-执行-反馈”地自主完成多步骤工作。这种范式转变对于开发者生态的潜在影响是巨大的。
- 原生多模态与生成式交互
Gemini 3彻底摒弃了外挂式视觉/听觉编码器的方案,采用了极致的原生多模态架构。
这意味着文本、代码、图像、视频和音频在模型底层共享同一套“世界模型”。这种深度的模态融合使其具备了惊人的感知能力,它不仅能转录3小时的会议视频,还能精准识别不同说话人的语气,甚至从模糊的低质量文档照片中无损提取结构化数据。
更具革命性的是Generative UI的引入:模型不再局限于返回文本或静态图片,而是能根据用户的意图,实时编写前端代码并渲染出动态的、可交互的界面(如对比图表、交互式地图或定制小组件)。这标志着人机交互界面将从“预制菜单”时代进入“即时生成”时代,UI本身变成了模型输出的一种动态语言。
同时,Gemini 3显著扩充其上下文长度至百万级,使模型能够在无需分段的情况下直接处理一本书的全文、完整代码库或长时间音视频的逐字稿。这为处理长文档理解、跨文档分析以及长对话记忆等应用场景提供了可能。
- 全方位自研硬件体系
在硬件支持方面,Gemini 3在Google自研的TPU(Tensor Processing Unit)上训练。TPU是为大型模型特别设计的高带宽、高并行计算芯片,其集群可以将庞大的训练任务拆分到数百上千个芯片上并行处理。借助TPU的强大算力和高效并行,Google得以在相对可控的时间内完成对Gemini 3 Pro的训练,同时通过硬件优化实现能耗与成本的平衡。