xbench评测集正式开源
三周前,我们正式推出了xbench,一款致力于量化AI系统在真实场景的效用价值,以及采用长青评估机制的AI基准测试。
这期间,从大厂到创业公司,从大模型研究者到AI Agent开发者,我们收到了来自海内外的大量咨询,特别是希望使用xbench评测集对他们的产品进行测试的需求与日俱增。
把红杉投资团队进行内部测评的工具打造成一款公开的AI基准测试,用公开透明的方式吸引更多AI人才和项目的共创,是我们打造xbench的初衷。我们相信开源精神可以让xbench更好地进化,为AI社群创造更大的价值。
因此,红杉中国今天正式开源xbench的两个评测集xbench-ScienceQA和xbench-DeepSearch。未来,我们将基于大模型和AI Agent的发展情况不断动态更新评测集,并且采用“黑白盒”机制,既保证xbench的发展可以服务更多的大模型和Agent开发者,同时尽力避免静态评测集经常出现的过拟合问题,确保xbench的长期有效。
开源地址
- 1. website:https://xbench.org/
- 2. github: https://github.com/xbench-ai/xbench-evals
- 3. huggingface:
一、评测集xbench-ScienceQA和xbench-DeepSearch的特点
01
随着推理模型的飞速发展,经典学科评测集如MMLU、MATH等已接近满分,无法继续度量模型能力的进展。博士研究生水平的学科知识和推理能力评测集如GPQA、SuperGPQA、HLE等成为新的评测标准,获得了业界的认可与关注。考虑到研究生水平的题目数量少,出题难,答案验证困难,且发布后缺少定期更新的机制,无法有效检查评估集污染的程度,红杉中国邀请了来自顶级院校的博士研究生以及资深行业专家,收集整理了来源可靠、多学科、搜索引擎未收录、答案明确的高质量题库,并将此成果开源发布为xbench-ScienceQA评测集。这个评测集的特点是:
- 专业题目构建:组织邀请来自顶级院校的博士研究生以及资深行业专家出题,并采用LLM难度检验、搜索引擎检验、同行检验等方式确保题目的公正性、区分度与正确性。
- 题目难度高、区分度好:整体平均正确率仅为32%,其中正确率不足20%的题目占三分之一。实测显示,不同推理模型的得分差距显著,跨度超过30%。
- 持续更新长期维护:每月榜单中持续汇报最新模型的能力表现,每季度至少更新一次评估集。同时,为了避免刷榜行为影响评测的公正性,我们在内部维护了一个闭源的黑盒版本,如果开源和闭源的排名相差较大,我们将会从榜单中移除相关排名和分数,以保证榜单结果的可信
02
自主规划(Planning)→信息收集(Search)→推理分析(Reasoning)→总结归纳(Summarization)的深度搜索能力,是AI Agent通向AGI的核心能力之一。然而,这一能力的复杂性也为评估工作带来了更高的挑战。当前,业界主流评测集侧重于基座模型的能力评估,高质量的Agent评测集相对稀缺。为了更好地考察Agent的深度搜索能力,红杉中国推出并开源了xbench-DeepSearch评测集。这个评测集的特点是:
- 针对Agent设计:题库中所有题目都需要Agent综合运用规划+搜索+推理+总结的端到端能力来解决。现有的知识搜索类基准测试(如SimpleQA)主要测量模型检索简单事实的能力,不依赖高阶的规划+推理能力,对于当下模型来说过于简单,评测分数早已饱和。
- 专注深度搜索能力:与GAIA等综合评测集不同,xbench-DeepSearch定位深度搜索能力的评估,在题库设计时特别针对搜索空间的广度和推理深度进行了充分考量,帮助Agent开发者更精准地拆解Agent能力维度,快速定位性能瓶颈和优化方向。
- 适配中文互联网环境:由于搜索与本地内容的信源质量高度相关,相比于同样定位深度搜索能力的BrowseComp评测集,xbench-DeepSearch弥补了其中文语境搜索题库不足的弱点。
- 全新出题人工验证:所有题目经由来自各行各业的专家人工出题,并由博士生交叉验证,力求题目的新颖性和主题的多样性,答案的正确性和唯一性,方便自动化评测。
- 持续更新长期维护:每月榜单中持续汇报最新模型的能力表现,每季度至少更新一次评估集。同时,为了避免刷榜行为影响评测的公正性,我们在内部维护了一个闭源的黑盒版本,如果开源和闭源的排名相差较大,我们将会从榜单中移除相关排名和分数,以保证榜单结果的可信度。
二、ScienceQA和DeepSearch的详细介绍
1. xbench-ScienceQA
一个动态更新、持续汇报评估结果的科学与工程问答Benchmarks
题目构建方法
- 在xbench-ScienceQA评测集搭建过程中,我们邀请了数十位不同学科或产业背景的硕士和博士参与出题,题目围绕自身擅长领域,可以来自私有数据与文献、领域定向的数据库或者是自己创造。此外,我们要求出题人在多个搜索引擎中搜索题目,确保答案不会直接出现在搜索结果中。
- 每个提交的新题目,会选择多个模型进行测试。确认有至少一个模型做对,一个模型做错,即会加入评测集。如果全部模型错误,我们会再进一步邀请该领域专家进行人工审核,进而决定是否选用。
- 针对准确率非常低的题目,我们会进一步与出题人确认题目来源与解题过程,同时会让与出题人同领域的人对题目进行审核,确保题目正确。同时,也会要求非同行评审,确保非同行无法仅依靠搜索引擎找到答案。
- xbench-ScienceQA评测集分为客观题和选择题。客观题要求具备明确、可评估的答案信息(如数字、专业名词、表达式等);选择题中我们优先选择了多选题和至少有5个以上选项的单选题,以降低模型“蒙对”的正确率。
学科和难度分布
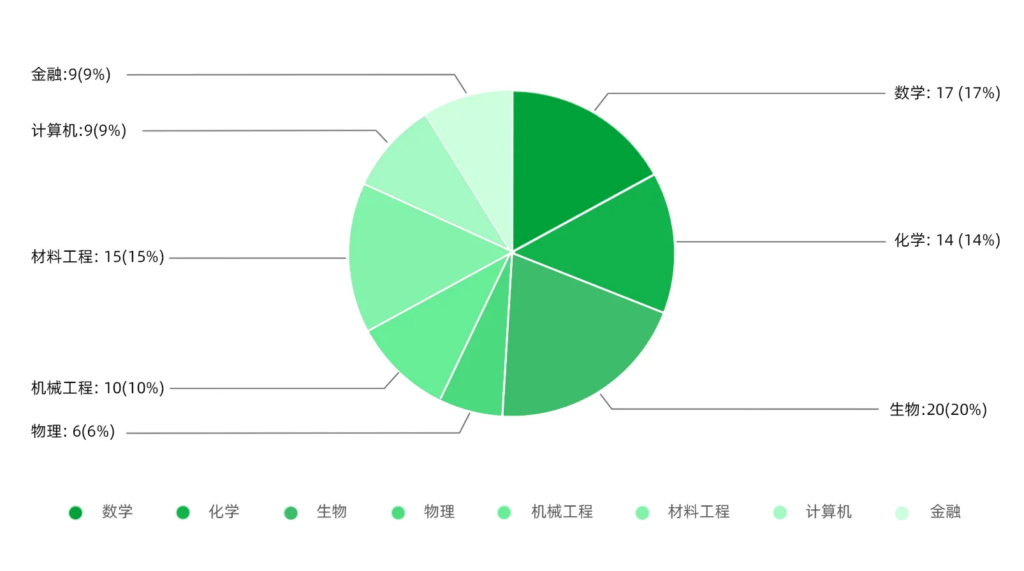
- 学科分布:xbench-ScienceQA评测集主要聚焦于STEM学科,包含了数学、物理、化学、材料工程、计算机等在内的8个主流学科,并尽量保持学科间题目数量的均衡。
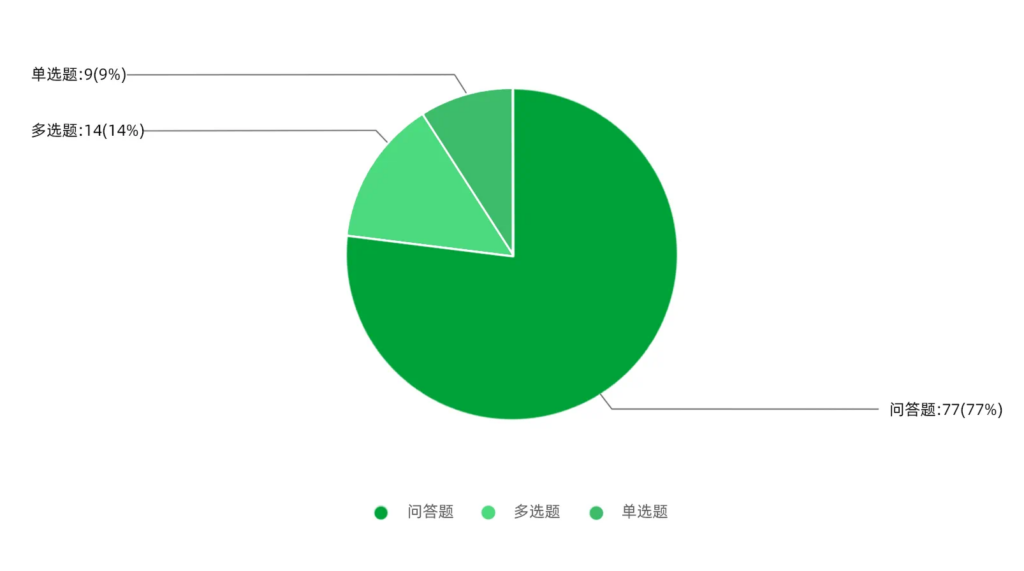
- 题型分布:xbench-ScienceQA评测集包含77道问答题,14道多选题以及9道单选题。由于单选题对BoN指标干扰较大(一个随机四选一的模型,在单选题的BoN上都能近似得到满分),我们尽量降低了单选题的比例。
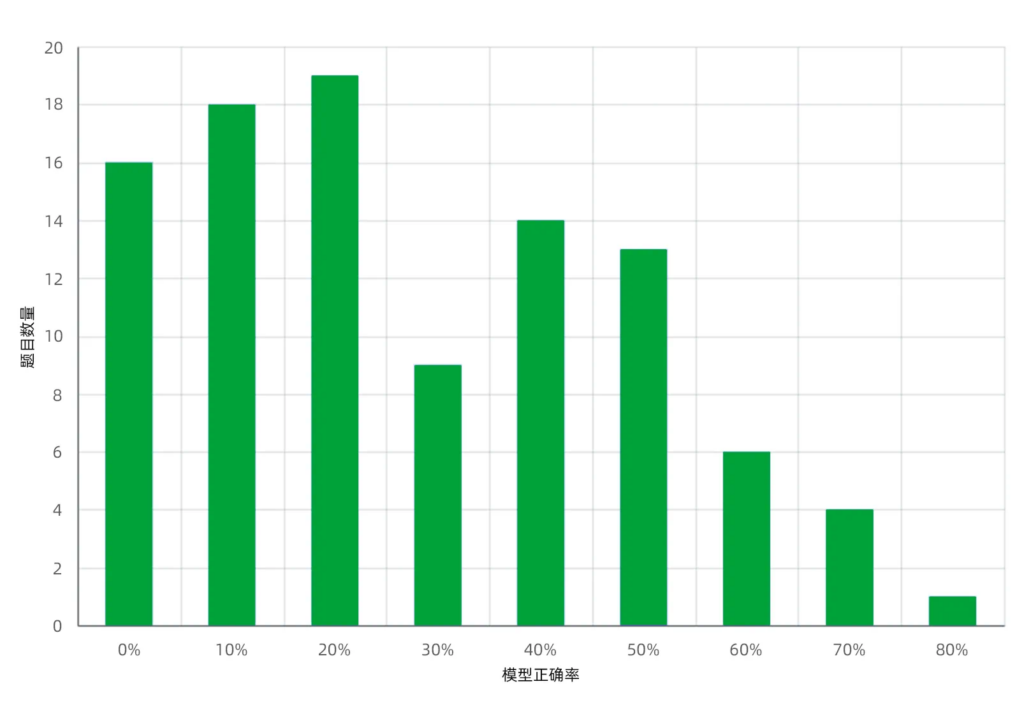
- 难度分布:根据所测模型的准确率结果,可以计算出每道题的模型正确率。该正确率可以作为题目难度的估计。最终的题目难度分布如下图,横轴是题目的模型正确率,纵轴是题目的数量。平均正确率是32%,低于20%正确率的题目占34%,并且在不同难度层次上均有区分度。
2. xbench-DeepSearch
一个无污染的衡量AI Agent深度搜索能力的基准测试工具
题目构建方法
- 在xbench-DeepSearch题目构建过程中,我们邀请了来自各行各业的数十位专家志愿者,依照我们给定的标注手册进行出题。所出题目要求使用搜索引擎进行验证,保证不存在原题或是直接能够检索出答案。
- 为了保证题目具备难度和区分度,所有题目均需要经过主流模型的测试验证,淘汰正确率>80%的题目。
- 深度搜索的难题,一般涉及搜索空间大,或者推理的步骤多。因此出题者在出题时,会被指引尽量提供满足这两个条件之一的题目,以增加题目难度。
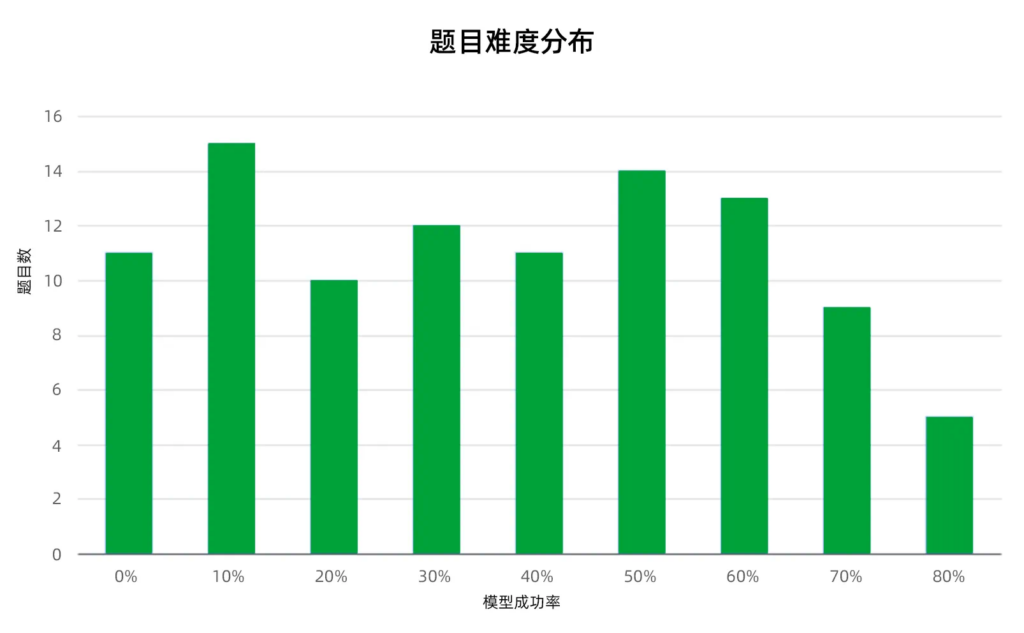
主题和难度分布
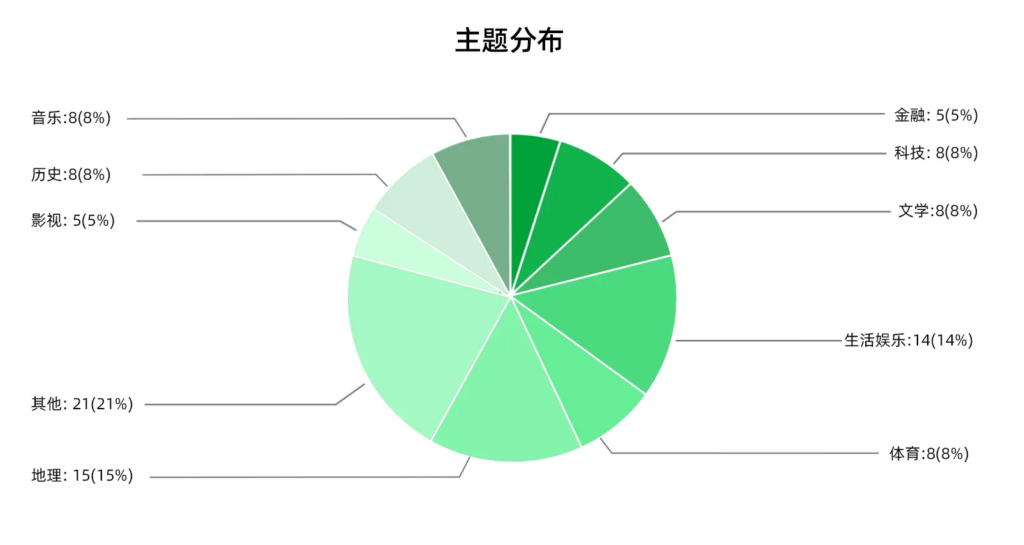
- 主题分布
- 为了保证题目主题类型的多样性,我们参考了OpenAI BrowseComp评测集的分类,鼓励出题者围绕他们喜好的主题出题,不仅能够提高题目的质量和准确性,也帮助每个分类获得足够的题目覆盖。最终的题目类型分布见下图:
- 难度分布
- 根据所测模型/Agents的准确率结果,可以计算出每道题的模型成功率。该成功率可以作为题目难度的估计。如下图中,横轴是题目的模型成功率,纵轴是题目的数量。
- 另一种难度估计方法,是统计真人解决问题所花的时间。该方法更接近人类对难度的感知,但缺点在于对评测同学领域知识的要求较高,一个行业内的同学和行业外的同学在解决问题时所花的时间差距很大,容易导致错误估计。我们计划在下次评测中给出真人所需耗时,作为难度分布的参考。
三、例题分析
1. ScienceQA例题及解析
示例1:

- 题目来源:本题的知识点基于2023年发表在IEEE 64th Annual Symposium on Foundations of Computer Science (FOCS) 的最新学术进展 A Randomized Algorithm for Single-Source Shortest Path on Undirected Real-Weighted Graphs
- 难度信息:本题难度较高,在所有被测模型上的平均正确率和BoN (N=5) 正确率,均低于5%
- 题目解析:要答对此题,则模型必须知道该文章的存在,并能够正确从论文文本提取出正确的算法复杂度。大多数被测模型不具备该长尾知识,因此回答了已经被该文章突破的O(m+nlogn)复杂度,另有个别模型虽然关注到了目标论文,但是不能提取正确的最优结果。
示例2:

- 题目来源:某大学 深度学习理论课程 课后作业
- 难度信息:本题在所有被测模型上的平均正确率低于20%、BoN (N=5) 正确率低于30%
- 题目解析:Vapnik–Chervonenkis复杂度是统计学习理论中的重要组成部分,广泛存在于互联网博客、公开教科书等信息源中。本题在经典例题“计算坐标轴对齐矩形的VC维度”(答案为4)的基础上加入嵌套矩形的新定义,考验模型灵活推理的能力。要答对此题,需要应对两步挑战:将原先的4组数据推广至8组,并在二维坐标系中构造新的数据点打散(shattering)方式。答错的模型通常只能机械地套用定义,但不能在更复杂的嵌套结构中构造最优解。
示例3:

- 题目来源:某年某省 化学奥林匹克竞赛 预赛试题
- 难度信息:本题在所有被测模型上的平均正确率低于20%、BoN (N=5) 正确率低于40%
- 题目解析:本题四个选项从多个角度考察了物质结构的相关知识。要答对此题,需要模型对涉及到的所有知识点均能做出正确判断。我们对选择题采用了“只要出现错误答案即得0分”的评分方式以降低偶然性,因此很多模型虽然判断对了其中的2-3个选项,但所具备的长尾知识不够丰富,在评测集中仍不得分。
2. DeepSearch例题及解析
- 在部分出题过程中,我们参考了BrowseComp中使用的“想谜底,出谜面”的思路,鼓励出题者先根据给定的主题,随机想一个可以验证的事实谜底,然后根据谜底设计谜面。
示例:出一道考察搜索广度的题目
步骤一:先确定谜底为两位诺贝尔奖获得者大卫・贝克(David Baker)和大卫・维因兰德(David Jeffrey Wineland)
步骤二:设计有限的限制条件,引导模型在一个合理的搜索空间内进行深度搜索。这两位诺贝尔奖获得者,一位获得了物理学奖,一位获得了化学奖;两位都曾就职于华盛顿大学;最后加上两者的出生日期差别以保证答案的唯一性,这样一道搜索广度的题目就构建完成。
最终构建的题目为:一位诺贝尔物理学奖得主同一位诺贝尔奖化学奖得主的年龄相差6799天,他们两位有相同的first name,曾就职于同一所位于美国西岸的大学,请问这两位诺贝尔奖得主是谁?
- 反之,另一种出题方式,是先想出谜面,逐步增加谜面的复杂度,最后设计出谜底来增加推理的深度。
示例:出一道考察推理深度的题目
步骤一:先确定一个出题者感兴趣的主题,如一件历史文物“赵怀满夏田契”
步骤二:为了考察推理深度,可以设计多层递进的条件。这件文物中记载了一个年份贞观十七年(公元643年),然后搜索该年份有什么重大的历史事件,可以搜到唐朝的名相魏徵去世,然后搜索魏徵,找到关于他的一个小众的事实点进行考察。
最终构建的题目为:有一个被剪做鞋样的历史文物,对研究唐代均田制起到了重要的作用,这个文物中记载的年份,有一位唐朝的一代名相去世,请问这位名相有几个儿子?
示例1:

- 题目来源:志愿者提供的新题
- 难度信息:本题在被测产品上的平均正确率约为33%
- 题目解析:本题较好地考察了模型的“规划→搜索→推理分析”的能力。模型需要能够规划出第一步确定三个省份各自有哪些地市级行政单位,第二步针对每个地市级单位,确认是否与外国接壤。两个步骤都需要有较好的搜索和推理分析能力才能获得正确答案。由于涉及的地市较多,且需要逐一搜索相关网页信息确认,侧重于模型搜索广度能力的考察。
示例2:

- 题目来源:志愿者提供的新题
- 难度信息:本题在被测产品上的平均正确率为47%
- 题目解析:本题考察模型的规划和推理分析能力。需要能够规划出正确的分析步骤:第一步确定尼米兹级航母的下水时间,第二步根据时间确定有哪几任美国总统在职,第三步确定有海军服役经历的总统,第四步确定平均服役时间。每一步的搜索都比较简单,不涉及广度搜索,重在推理深度能力的考察。
四、欢迎加入xbench,一起探索AI发展的最前沿
从2016年AlphaGo在围棋比赛中击败韩国名将李世石,到2022年ChatGPT的横空出世,AI在近些年迎来了一波高速发展的爆发期。
正所谓“AI一天,人间一年”,AI自我迭代的效率,已经远远超过人类过去大多数技术更新的速度。今天,在我们开源xbench的同时,希望号召更多评测爱好者、Agent开发者和AI研究者参与其中,一起去观察、试验和应用AI发展最前沿的技术和产品。
- 如果您是评测爱好者,想要参与到评测集的建设中;
- 如果您是模型或者Agent开发者,想要提交您的产品参与评测,或者提交白盒分数;
- 如果您希望给我们反馈意见,对题目或评估结果有疑问;
- 面向垂直领域智能体的Profession Aligned评测,xbench-Profession-Recruitment和xbench-Profession-Marketing暂未开源。但欢迎已经发布的模型或者Agent开发者,通过邮件联系我们进行提测,测评完毕后将会告知其分数。
欢迎联系team@xbench.org,我们会尽快反馈。